
1. 摘要
从临床诊断到公共安全,各种实际场景都需要多模态图像。然而,由于成像条件的限制,某些模态可能不完整或不可用,这通常会导致许多实际应用中的决策偏差。尽管现有图像合成技术取得了重大进展,但从多模态输入中学习互补信息仍然具有挑战性。为了解决这个问题,我们提出了一个基于自编码器的联合注意力生成对抗网络(ACA-GAN),它使用可用的多模态图像来生成缺失的图像。联合注意机制采用单模态注意力模块和多模态注意力模块,有效地从多个可用模态中提取互补信息。考虑到显著的模态差距,我们进一步开发了一个自编码器网络来提取目标模态的自表示,引导生成模型融合来自多个模态的目标特定信息。这大大提高了与目标模态的跨模态一致性,从而提高了图像合成性能。通过对各种多模态图像合成任务的定量和定性比较,展示了我们的方法比几种先前方法的优越性。
2. 方法
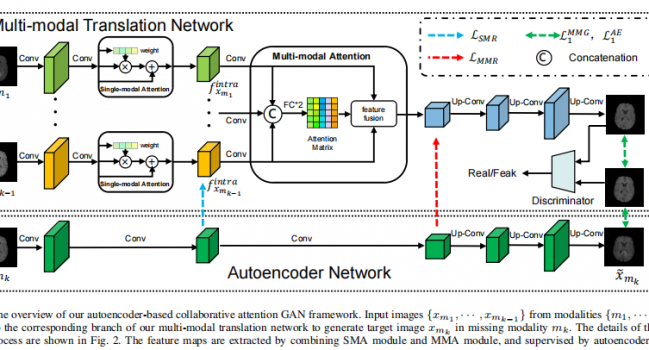
我们的ACA-GAN框架由多模态翻译网络和自编码器网络组成,如图1所示。为了融合特定于目标模态的多模态表征,我们首先设计了一个多模态注意力模块,从多模态图像中提取模态间的互补信息。为了实现这一目标,我们开发了单模态注意力模块来提高每个模态的特征兼容性。考虑到自编码器强大的自表示能力,我们将其与多模态翻译网络平行放置,以提高跨模态一致性。因此,该翻译模型可以有效地融合来自多种输入模态的目标模态特定信息。
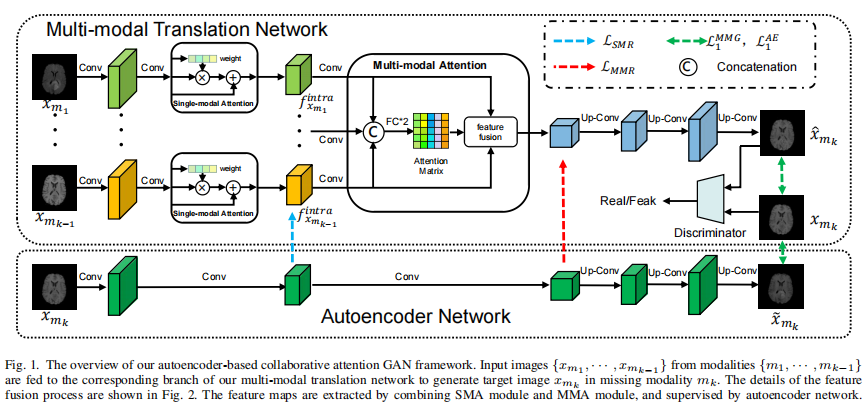
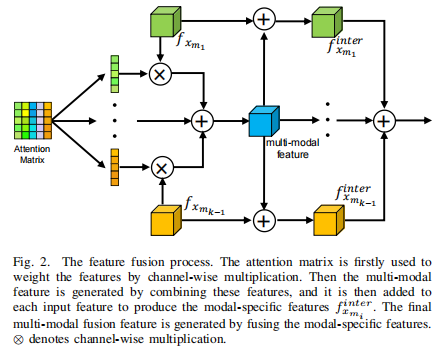
图2进一步展示了图1中特征融合的过程
3. 实验
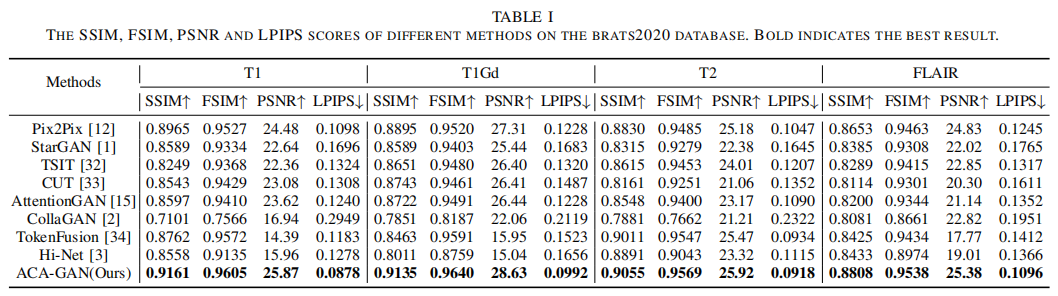
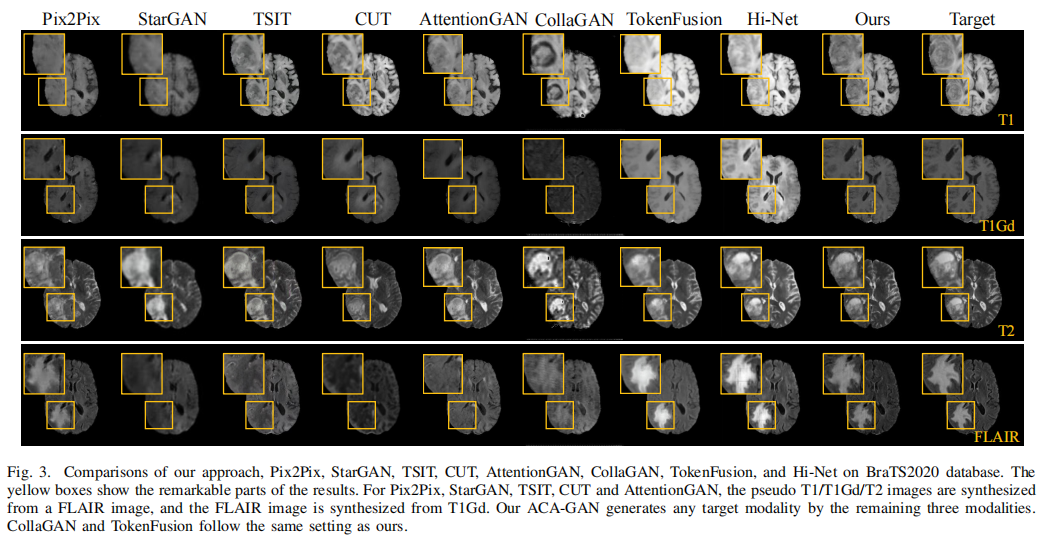
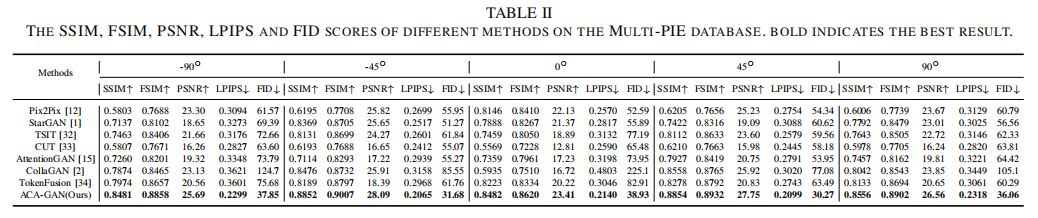
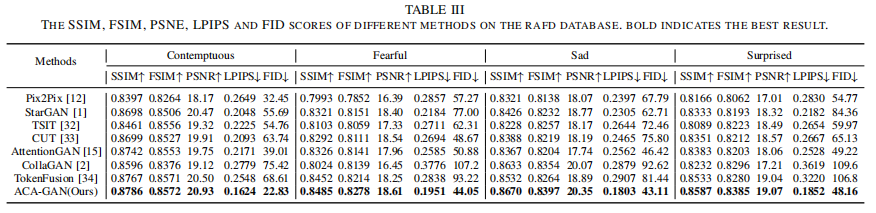
本文在三个多模态图象合成任务上验证了本文方法的有效性:医学图象合成(BraTS2020),光照图象合成(MultiPIE)和表情图像合成(RaFD)