论文题目:Boosting Pseudo Labeling with Curriculum Self-Reflexion for Attributed Graph Clustering
作者:朱鹏飞,李佳璐(博士研究生),王煜,肖斌,张敬林,林婉瑜,胡清华
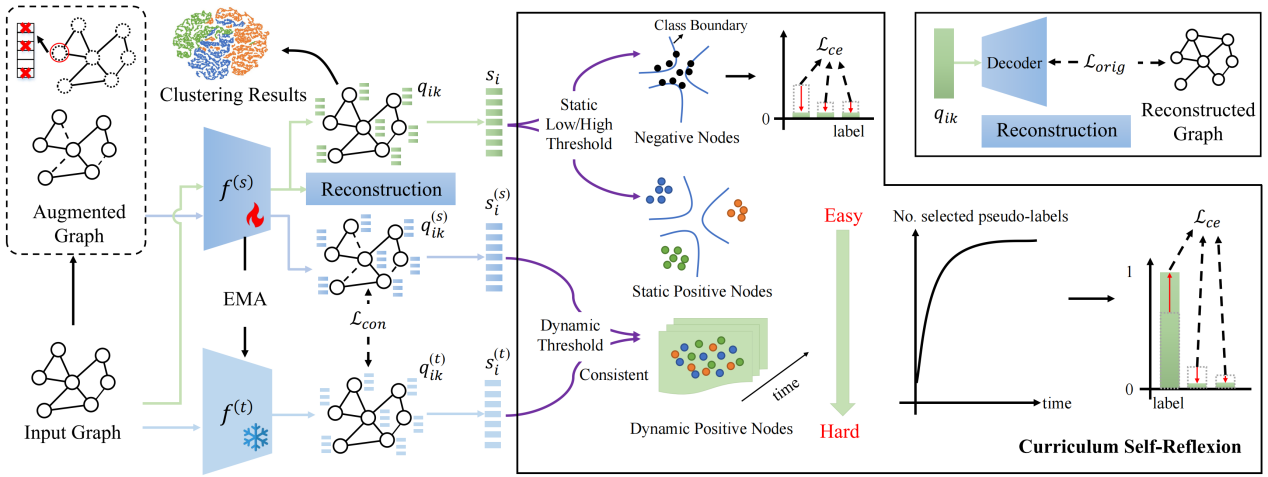
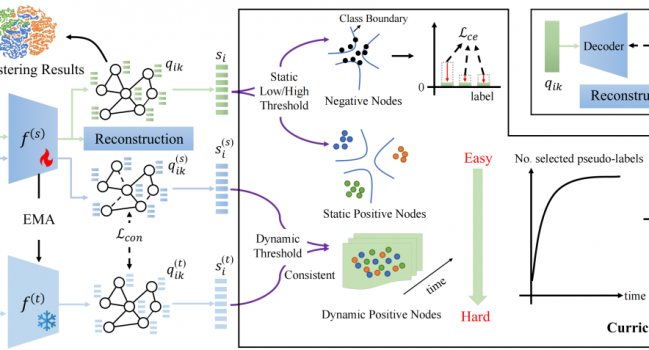
论文概述:属性图聚类是一种无监督学习任务,旨在将图的各个节点划分为不同的组。现有方法侧重于设计各种借口任务来获得合适的监督信息进行表征学习,其中预测式方法显示出很大的潜力。然而,这些方法(1)会产生对聚类目标的辅助任务偏差;(2)由于静态阈值的设置而引入标签噪声。为了解决这个问题,我们提出了一种新的自监督学习方法,即基于课程自我反思的伪标签设计方法(PLCSR),该方法通过挖掘模型自身信息来学习可靠的伪标签,以自我反思的方式实现节点的渐进式处理。首先,利用原始编码器参数的指数移动平均构造自辅助编码器来代替辅助任务,这为寻找高置信度伪标签提供了额外的视角。其次,设计了一种基于动态阈值的课程选择策略,以更准确地充分利用图节点。除了在初始阶段选择的高置信度简单节点外,还为两个编码器产生一致预测的困难节点分配伪标签,以避免欠学习问题。对于其他高不确定的困难节点,模型不做判断以尽量减少对优化的不利影响。大量实验表明,PLCSR显著优于最先进的预测式方法CDRS,在聚类准确率方面提高了6%以上。