论文《Robust Multi-Drone Multi-Target Tracking to Resolve Target Occlusion: A Benchmark》被IEEE Transactions on Multimedia录用
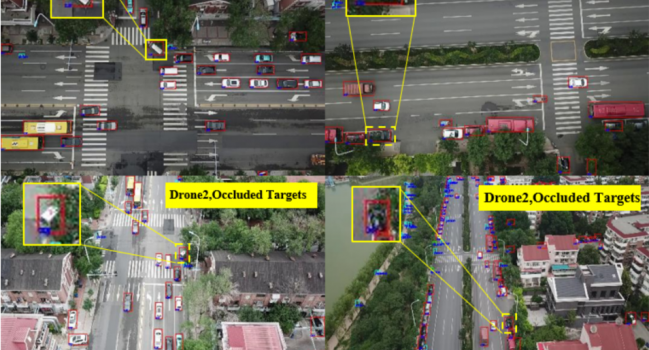
1 引言 多无人机多目标追踪是协同环境感知领域重要的研究方向,其目的是实现多视角信息融合,克服单架无 …

1 引言 多无人机多目标追踪是协同环境感知领域重要的研究方向,其目的是实现多视角信息融合,克服单架无 …
论文下载与视频链接: https://dl.acm.org/doi/10.1145/3503161. …
@article{cao2024visible,
title={Visible and Clear: Finding Tiny Objects in Difference Map},
author={Cao, Bing and Yao, Haiyu and Zhu, Pengfei and Hu, Qinghua},
journal={arXiv preprint arXiv:2405.11276},
year={2024}
}
<pre>
@ARTICLE{Gao22LUSS,
author={Gao, Shanghua and Li, Zhong-Yu and Yang, Ming-Hsuan and Cheng, Ming-Ming and Han, Junwei and Torr, Philip},
title={Large-scale Unsupervised Semantic Segmentation},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
year={2023},
volume={45},
number={6},
pages={7457-7476},
doi={10.1109/TPAMI.2022.3218275}
}
</pre>





