论文题目:CKD: Contrastive Knowledge Distillation from A Sample-Wise Perspective
作者:朱文成,周鑫(硕士研究生),朱鹏飞,王煜,胡清华
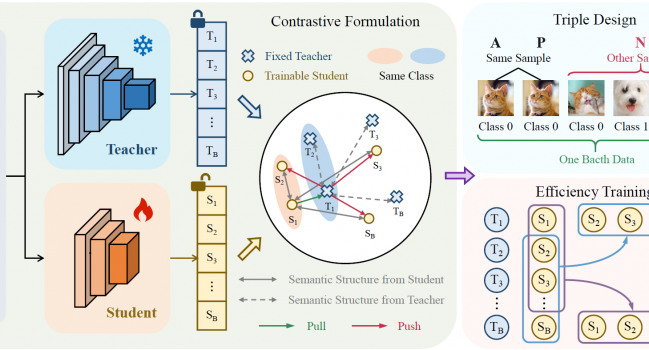
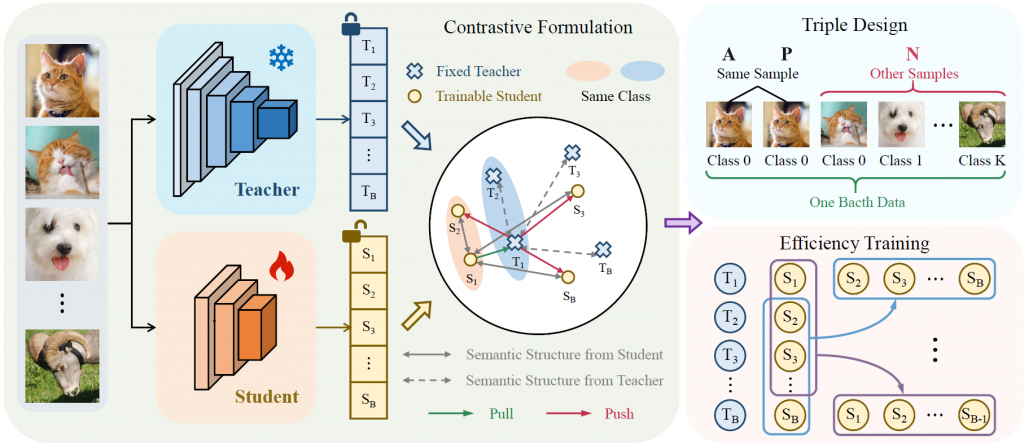
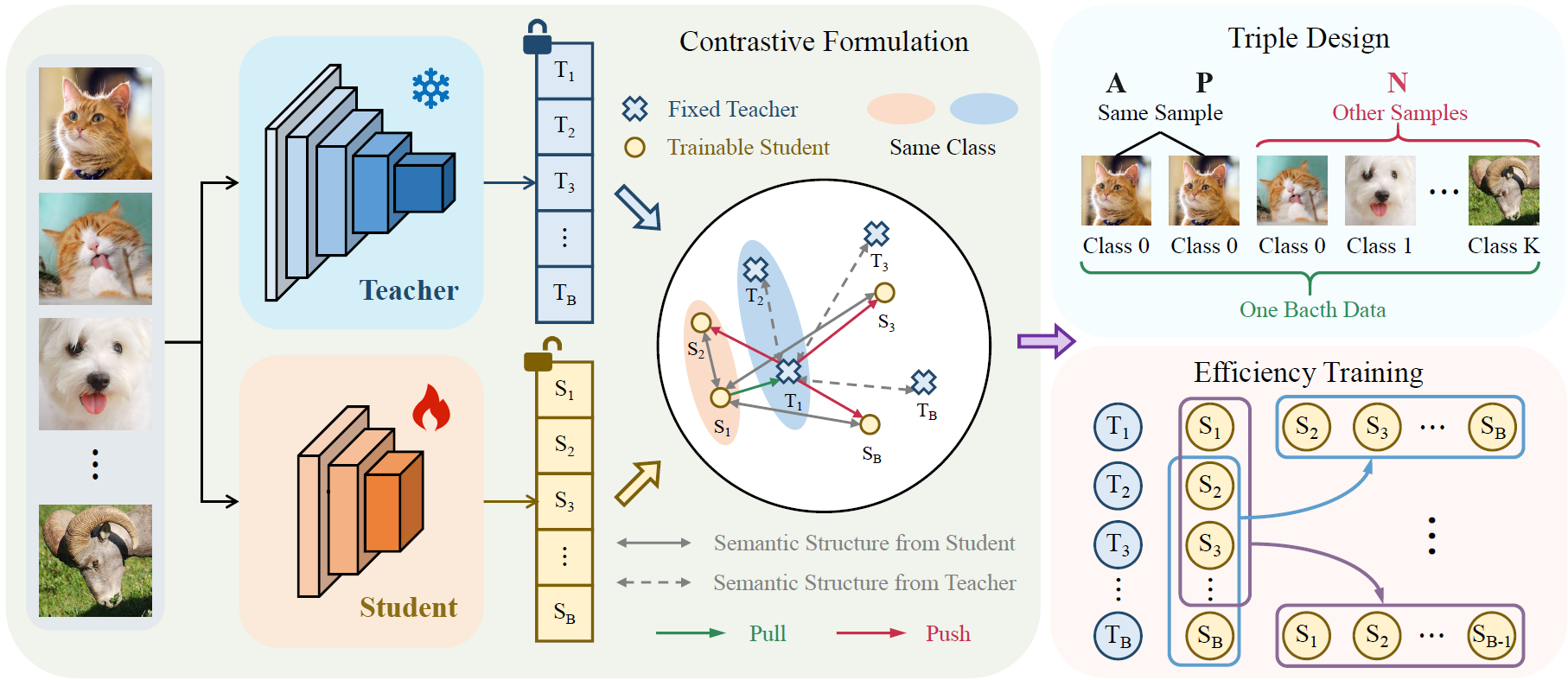
论文概述:近期,团队提出了一种简单而有效的对比知识蒸馏框架,该框架在实现样本级logit对齐的同时保持了语义一致性。传统知识蒸馏方法过度依赖样本层面的特征相似性,存在过拟合风险;而对比学习方法则侧重于类间区分,却牺牲了样本内部的语义关联。我们的方法通过师生模型的样本级对比对齐来传递”暗知识”。具体而言,本方法首先通过直接最小化单个样本内师生模型的logit差异来实现样本内对齐。随后,利用样本间对比来保持跨样本的语义差异性。我们将正样本对定义为来自同一样本的师生模型对齐logit,负样本对定义为跨样本的logit组合,从而将这两个约束条件重新表述为InfoNCE损失框架。这一设计不仅将计算复杂度降低至低于样本平方量级,还消除了对温度参数和大批量大小的依赖。我们在三个基准数据集(包括CIFAR-100、ImageNet-1K和MS COCO)上进行了全面实验。实验结果表明,该方法在图像分类、目标检测和实例分割任务上均展现出显著的有效性。
@article{cao2024visible,
title={Visible and Clear: Finding Tiny Objects in Difference Map},
author={Cao, Bing and Yao, Haiyu and Zhu, Pengfei and Hu, Qinghua},
journal={arXiv preprint arXiv:2405.11276},
year={2024}
}
<pre>
@ARTICLE{Gao22LUSS,
author={Gao, Shanghua and Li, Zhong-Yu and Yang, Ming-Hsuan and Cheng, Ming-Ming and Han, Junwei and Torr, Philip},
title={Large-scale Unsupervised Semantic Segmentation},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
year={2023},
volume={45},
number={6},
pages={7457-7476},
doi={10.1109/TPAMI.2022.3218275}
}
</pre>