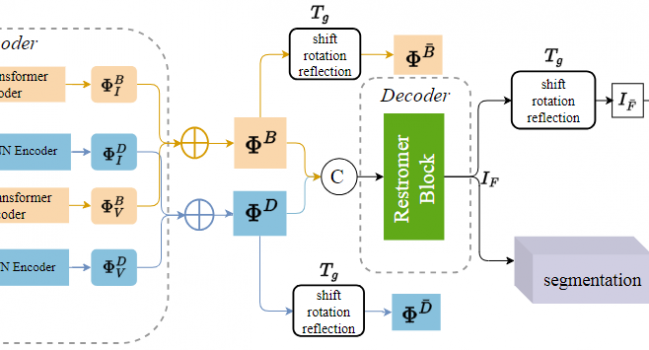
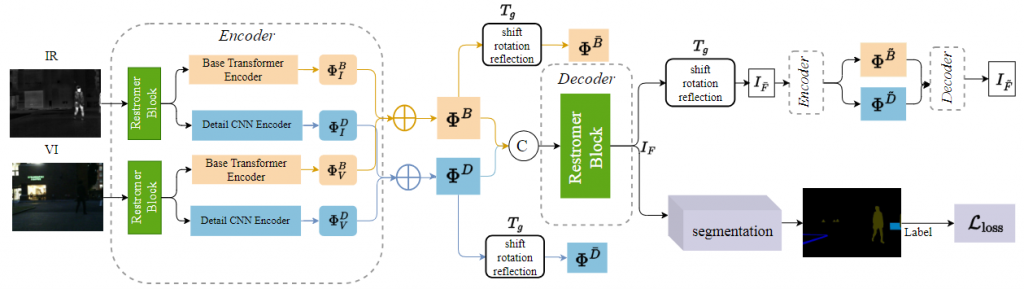

论文题目:TEDFuse: Task-Driven Equivariant Consistency Decomposition Network for Multi-Modal Image Fusion
作者:孙一铭,崔新语,王振,程昊,董永峰,朱鹏飞,李凯
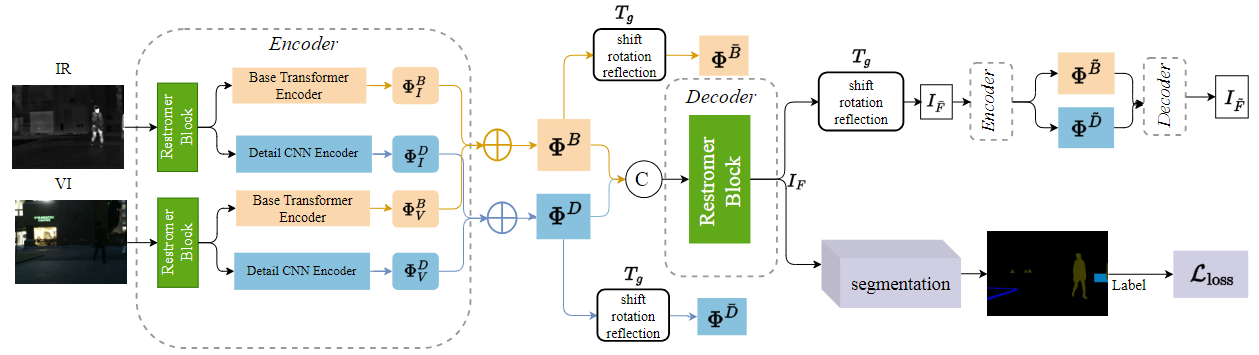
论文概述:多模态图像融合旨在利用红外和可见光模态的互补优势生成场景表示更优的图像。然而,大多数现有的融合技术主要关注像素级的融合,往往忽视了源图像和融合图像之间语义一致性的保持。为了解决这一局限性,我们提出了TEDFuse,这是一种任务驱动的等变一致性分解网络,可确保图像空间内和跨高级语义任务的语义一致性。TEDFuse包含两个关键部分:首先是一个具有等变一致性的鲁棒分解框架,确保融合后的图像在平移、旋转和反射的情况下保持一致的变换属性,从而加强局部细节的保留和全局语义的一致性;此外,提出的任务驱动的融合框架集成了语义分割网络模块,通过语义损失函数加强语义特征的保留,并确保分割等下游任务特征表示的一致性。所提出的方法不仅保留了融合图像的语义一致性,还提高了下游应用任务的性能,在复杂视觉应用的多模态融合中展现了卓越的能力。大量融合、下游评估实验及模型剪枝实验验证了所提出的TEDFuse模型的有效性。
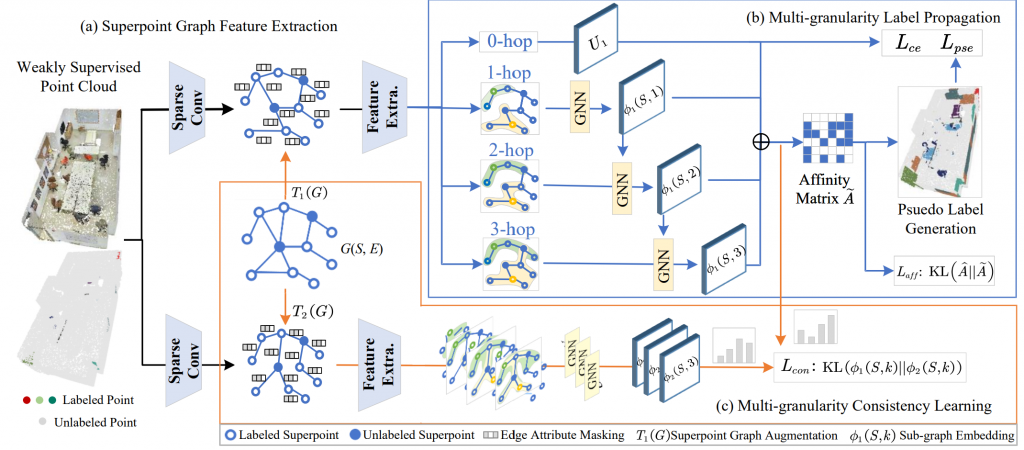
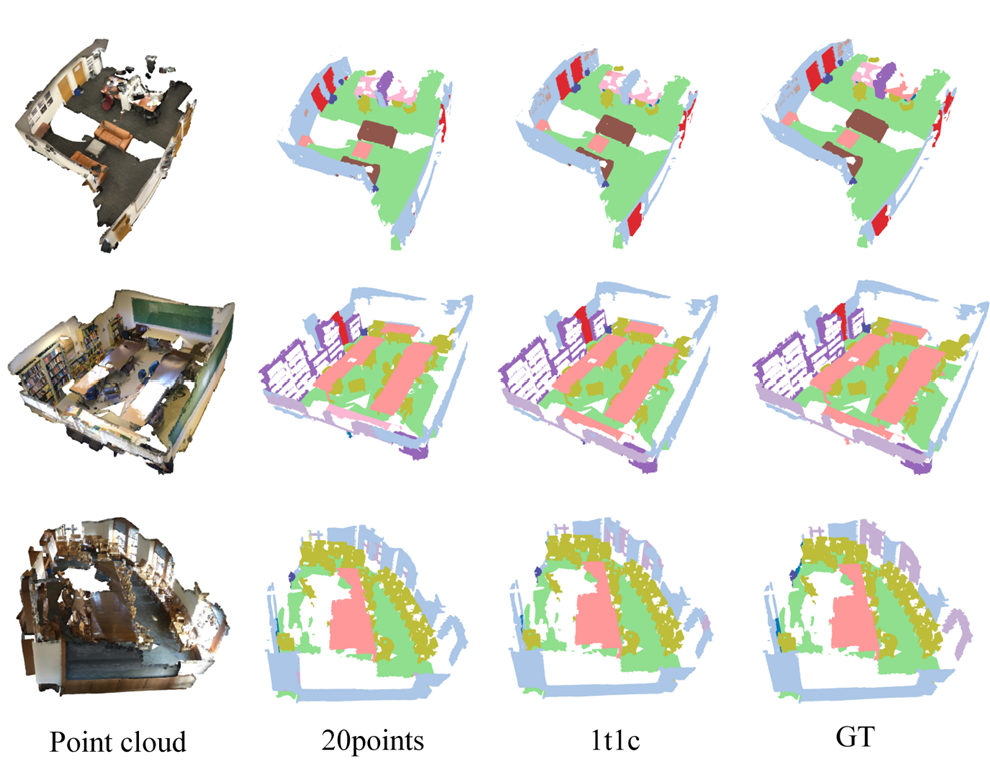
论文题目:Multi-granularity Superpoint Graph Learning for Weakly Supervised 3D Semantic Segmentation
作者:范妍,王煜,朱鹏飞,惠乐,谢晋,肖斌,胡清华
论文概述:弱监督的三维语义分割已被证明在减轻对密集标注的高度依赖方面是有效的,主要通过生成高质量的伪标签。然而,由于点云场景的复杂性和无序性,仅依赖模型的语义预测或手工设计的特征相似性来生成伪标签效率低下且容易产生偏差。这一限制不可避免地导致伪标签不准确。为了解决这个问题,我们提出了一种新的方法,称为多粒度超点图学习(Multi-granularity Superpoint Graph Learning, MSGL),该方法利用点云的多尺度局部特征来提升伪标签的质量。我们首先在超点图上设计了一个多粒度的局部表示学习模块,以捕捉复杂场景中每个超点的邻域结构信息。随后,所生成的结构嵌入被用于增强标签传播过程中的亲和矩阵,从而生成高质量的伪标签。为了进一步提升结构表示模块在场景变化或数据波动下的泛化能力,我们在 MSGL 中引入了一种多粒度一致性损失函数。该损失在每个场景的不同超点图视图之间进行应用,以确保鲁棒且一致的学习过程。我们在三个基准数据集上进行的实验表明,所提出的方法在多种稀疏标注设置下优于现有的弱监督方法,且仅增加 1% 的计算开销就使得基线性能平均提升了 7.7%。此外,我们的方法即使在每个目标仅标注一个点的极端弱监督设置下,在性能上也优于部分全监督方法。
@article{cao2024visible,
title={Visible and Clear: Finding Tiny Objects in Difference Map},
author={Cao, Bing and Yao, Haiyu and Zhu, Pengfei and Hu, Qinghua},
journal={arXiv preprint arXiv:2405.11276},
year={2024}
}
<pre>
@ARTICLE{Gao22LUSS,
author={Gao, Shanghua and Li, Zhong-Yu and Yang, Ming-Hsuan and Cheng, Ming-Ming and Han, Junwei and Torr, Philip},
title={Large-scale Unsupervised Semantic Segmentation},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
year={2023},
volume={45},
number={6},
pages={7457-7476},
doi={10.1109/TPAMI.2022.3218275}
}
</pre>