


2021年12月12日,由中国计算机学会计算机视觉专委会主办的第11期CCF-CV“视界无限”系列活动——“智能系统环境感知的前沿进展与未来趋势”研讨会在线上成功举办,天津大学朱鹏飞副教授、张长青副教授担任执行主席。研讨会邀请了天津大学胡清华教授、专委会秘书长北京邮电大学马占宇教授致辞,西安交通大学薛建儒教授、西北工业大学韩军伟教授、武汉大学夏桂松教授、大连理工大学王栋教授、一飞智控(天津)科技有限公司研发总监吴冲博士做主题报告。天津大学胡清华教授等及以上五位讲者参与了深度研讨。计算机视觉专委会B站公众号对本次会议进行了全程直播,直播人气峰值达到3100+。

薛建儒教授的报告题目是“交通场景的理解与预测”。报告分为三个方面,首先,介绍了自动驾驶现阶段的发展情况以及在场景理解和情景预测等基础的问题;其次,是在视觉导航里视觉理解、场景理解所面临主要的难点问题;最后针对用于驾驶预测的交通情景的预测展开介绍。最后,薛建儒教授指出,自动驾驶正在不断落地应用。然而,实现真正的自主驾驶依然面临着诸多极具挑战性问题。本报告主要探讨自主驾驶的动态场景理解与预测问题,并报告课题组近年来所取得的一些研究进展。

韩军伟教授的报告题目是“AI赋能高分遥感目标检测与识别:挑战、对策及展望”。韩军伟教授指出,高分辨率遥感图像目标检测与识别是空天地海一体化观测系统的一项关键技术,广泛应用在侦察、监视、预警、搜救等军民领域。与自然图像相比,高分辨率遥感图像具有目标方向多变、目标类型及数量繁杂、特定领域样本稀缺(如导弹阵地)、成像视角单一等特点,此外,不同平台、不同光照、天气条件、大气参数等都会对遥感图像获取产生影响。这些综合因素使得高分辨率遥感图像目标检测与识别,与自然图像理解相比,面临着更大的挑战和更多的难点问题。本报告首先总结分析了高分辨率遥感图像目标检测与识别面临的挑战,重点汇报韩教授团队在旋转不变目标检测、有向目标检测、弱监督目标检测、小样本目标检测以及目标型号识别等方向取得的研究进展和典型应用,最后展望了未来的研究工作。
夏桂松教授的报告题目是“图像几何结构矢量化感知及应用”。夏桂松教授指出几何结构是诸多低、中层视觉计算任务的重要特征,在视觉场景结构理解和环境感知等方面有重要应用。本报告分享夏教授团队在自然图像几何结构(如wireframe、line segment、junction等)建模和计算问题上的新进展,包括图像junction、line segment的非监督计算模型和有监督深度感知方法、自然图像一维线结构与二维区域之间的对偶计算框架、wireframe的深度计算模型等,及其在室内图像三维重建、高分遥感图像解译等方面的应用。

王栋教授的报告题目是“高性能视觉跟踪算法探索”。视觉跟踪算法近年已取得突破性进展,但复杂现实环境中的各种场景变化和平台限制对跟踪算法提出了以“强鲁棒性、高精准度、易迁移性、低计算量”为导向的高性能要求。王栋教授团队近年来从针对鲁棒外观模型更新控制、模板和搜索区域特征融合、通用尺度估计模块设计及嵌入式平台部署需求这四方面开展研究,分别提出了元更新器模型、Transformer跟踪模型、Alpha-Refine尺度估计模块和NAS跟踪网络搜索模型,显著提升了跟踪算法精度的同时降低了参数量和计算量。

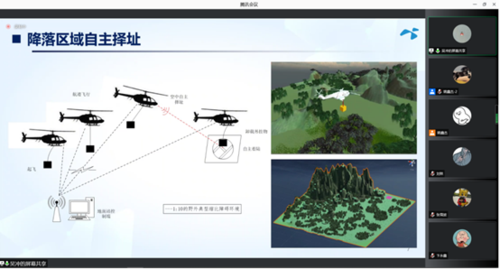
吴冲博士的报告题目是“环境感知技术在行业无人机中的应用”。吴冲博士指出,随着无人机行业应用的快速发展,环境感知技术对推动无人机应用的深入发展发挥着越来越重要的作用,报告中以不同行业无人机对环境感知技术的需求为牵引,从无人机对地安全探测、无人机紧急降落安全区域评估、多无人机协同定位、无人机拒止环境定位等多个方面介绍环境感知技术在无人机中的应用场景和应用方法。
在Panel环节,与会嘉宾就“智能系统的环境感知中复杂环境和开放环境应该怎么定义?”、“自主智能系统对于小目标或突发情况造成的感知困难怎么解决?”、“如何把环境感知与决策控制等相关学科做交叉研究?”、“智能感知系统中的大规模预训练模型”等问题展开热烈讨论,各位专家就上述问题分享各自的观点。
最后,第11期“视界无限”研讨会在中午12点20分圆满结束。
Panel 实 录
为了惠及广大的研究者,每期“视界无限”精选嘉宾观点进行分享,以下为本期研讨会Panel实录。
朱鹏飞:首先第一个问题是我们今天的主题是智能系统的环境感知,目前在智能系统环境感知里,经常提到两个关键词。第一个是复杂环境,第二个是开放环境。那对于这里面的复杂环境或开放环境,应该怎么去定义,是不是可以分为强开放和弱开放,这个问题想要请教一下各位专家。
薛建儒:各位老师好,参加这次讨论的前面几位专家的报告很有意义。那么我对第一个问题,谈一点自己个人的理解。因为对于自主智能系统来说,复杂系统、复杂环境、开放环境大家都会讲到,那这个复杂环境的复杂性我们主要是从问题的困难程度来讲的,它是一个比较普适性的词。那对于开放来说,实际上是从机器学习的角度来讲,主要还是在说在我们前期的训练数据中,它并不能包括在将来的测试中出现的类别、样例等等,这是开放。那对于自主智能系统来讲,开放环境这个场景里面出现的变化是不可预料的。当然要讲这个弱开放和强开放主要在于我们对于开放的度量。我们目前还没有一个比较清晰的度量和定量的指标。所以这个强和弱依然是一个比较定性的词。相对而言这个弱讲的是我们场景变化不是很大,而强是指不可预知的、未知的一个环境。这是我个人的一个简单的理解,跟大家一起来讨论一下。
夏桂松:各位老师好,我非常赞成薛老师说的。然后我做遥感的应用多一点,我们经常提这个复杂环境。这个复杂在遥感里面,比如说复杂环境地表,我们国家山地多,山地有百分之六十。这个在自动驾驶或者智能驾驶里面也会存在。比如说在不同的城市,它的地表是有明显的差异,在武汉都是平地比较多。但是如果在武汉这个环境下面做出来的模型,比如智能驾驶系统,在重庆或者成都这种山地多的地方,能不能好用?可能是一个问题。就像刚才薛老师说的,我觉得这是从问题上面来定义。开放环境的话,我们目前也做一些,比如说主要是针对目标识别或者是图像的语义分割,在开放环境下的检测和识别。开放环境下面,就像刚才薛老师说的,我们训练时候的假设,我们的训练集是一个封闭的,我们所有在测试的时候遇到的类别,或者遇到的语音信息在训练集里面都会见过,或者是见过相关的。但是可能在开放环境下面,我们不一定能够找到相关的这些类别信息或语义信息。怎么样把这个关联起来特别重要。这个我们在自己做,比如说遥感目标检测,或者是遥感的地物分类、识别的时候,这个问题特别明显。比如说我们在具体的场景应用中,有的目标根本就没有见过,特殊类型的飞机,特殊类型的车辆,没有见过或者根本就不可能见过。这种环境下面的目标的检测识别,或者是定位都是很难的。通过我们目前这个阶段的尝试,我觉得这个开放环境问题应该是后面在做具体的识别、分类,还有检测定位里面可能需要重点关注的一个问题。好,谢谢老师。
朱鹏飞:好,感谢夏老师。根据薛老师,还有夏老师的观点,我们对于这个复杂性和开放性确实在使用的过程当中,其实还是应该区分的,复杂性的话,是不是更侧重于我们这个环境里面的一些变化量,然后它这里面比较多元。然后对于这个开放性的话,我们其实在咱们国家这个新一代人工智能2030的计划里边,有关于这方面的一些项目,比方说连续学习在这里边关注新类别、新场景、新任务,这里面对于开放性,是更侧重于这个点的。这是关于复杂性和开放性的一个讨论。接下来的话,我们看下一个问题。下一个问题也是我们需要关注的一个点,在这个智能系统,尤其自主的这样一个智能系统的话,我们经常需要关注他的一个决策安全性。薛老师的报告里面也讲了这个理解和预测,还有一个决策。对于我们这个智能系统的感知里边,其实像跟踪里面它的一个目标可能很小;然后检测里面的话,对于这个微小目标来讲,它的检测都容易造成的误检漏检。那对于这样一些目标很小、不清晰,突发情况这样造成的一些感知困难。我们目前的这种系统里面应该怎么样去面对决策安全性问题。
吴冲:好的,朱老师。因为可能这个题目还是比较大,我们就做过一些这方面的尝试。就从无人机应用环境感知的这个技术点来讲,刚才报告里我也提了几句。因为无人机在实际飞的过程中,实际上对于安全性要求还是比较高的。如果说有一些探测失误,或者说比如不管是避障也好,还是探测也好,如果说有些失误就可能导致摔机。其实这个风险是比较大的。那么在我们的这个实际应用中,其实就有很多技术我们是想去用,而且绝对好用。但是在应用过程中,可能由于它的稳定性、可靠性达不到我们的预期。所以我们只能去放弃,这个还是比较普遍的。就举个很简单的例子,我们之前做农业质保的时候,开始的时候,很多人会说基于视觉去做这个避障。但是在实际的农田环境下,有很多比如电线、电线杆、树枝,这些从视觉角度很难去做。但最后就导致这个基于视觉的这个方案想用但是不敢用。那么最后实际上这个方案是通过换成激光雷达来解决的。这个我觉得算是一个例子吧,说要去解决这些问题。特别对于无人机来讲,我觉得一方面还是要去考虑多传感器的融合,来去提升它的稳定性,这个可能是一个基础。第二个说我们可能在做设计的时候,会考虑一些先验条件。要考虑这些先验条件在实际场景下到底适不适用?我觉得可能主要是这两点吧。
薛建儒:朱老师,我接着吴总刚才讲的这个问题。因为我们在做自动驾驶。实际上感知的困难对于决策的影响,这个问题确实也是一个开放的问题。从整个的发展的观点来看,目前这个问题的解决仍然还是在探索过程中。那么这里面,如果说我们单纯把这个感知看作单一的一个问题,从输入到输出结果,然后把这个结果再给决策的模块,那么这个不确定性它的这个难度是非常大的。当然刚才吴总提出了两个改进的措施,一个是做传感的融合,一个是先验的条件或者知识的引入,应该能够在一定程度上缓解这个问题,但对于最终能不能解决这个问题,我觉得还是值得去探讨的。因为我们的这个感知性能,现在有很多的公开的数据集,大家的性能指标也一直在提升。但它总是会碰到这个天花板。比如说我们在无人车里面,我们对三维,对障碍物的三维信息的检测,目前它并不足以去支持安全可靠的这个决策。这就使得我们要去思考一下,要借鉴一些新的东西。比如说认知大脑,那么我们人在开车的时候,也会出现看不清的情况,但为什么人能够避免这样的一个缺陷?因为感知上的这个缺陷,所以它存在一个反馈的机制。另外,存在一个知识的引入,所以我觉得可能要把感知和决策结合起来。尤其现在这个深度学习,它技术的发展,我觉得使得这个问题的解决还是有可能性的。比如说我们能够对于感知的这种不确定性和我们决策的不确定性,建立一个模型,在一个统一的框架下去思考它,有可能会得到一些好的方法。当然这个里面大家可能是需要从系统角度,比如我们碰到的对这个问题的研究的范围扩大了,我们要把决策和感知放在一起统一来考虑。所以它的问题的规模以及它求解的难度都会指数级上升。但是我觉得这可能是最终的一个技术路径。因为目前我们也在这一方面做一些探索,包括这个注意力机制,把反馈的这种能力引入到回环里面去,从感知到决策的回环里面去。那这是我的一个个人的观点,跟大家一起来探讨。他这方面这个进展仍然非常缓慢。无论是我们的研究还是整个领域里面的研究来讲,这也是自主智能系统所碰到的一个关键的问题,也是具有挑战性的问题。所以希望在后面和大家一起来共同探讨。好的,我就讲这儿。
王栋:薛老师介绍的非常好,我稍微补充一下,就我的理解薛老师说的感知决策一体化是一个非常好的思路。然后我们要解决这样的一个困难的话,也必须说感知决策这两方面,认知决策的两方面都要进行发展。我们通常会在实际中想到增加传感设备。那么就可能会越来越准,这是一个非常重要的解决实际问题的思路。但是我们在增加的过程中,也会发现这个多传感器融合带来的数据量的增加,成本的增加也是非常大的一个开销。所以把感知和认知一起,让认知也去指导和驱动感知也是非常重要的一个思路。然后第二个说我们要在关键场景中解决决策的安全性,可能也是在模型的可解释性方面也需要有更深入的一个考量。因为总听到很多做传统学科的,因为他们数据量比较小,他们总抱怨深度学习类的算法在我们这儿根本不可靠,还不如传统c v 的一些算法。他们现在在很多的设备检测中,特别是涉及一些工件检测等领域,他们很多的时候还是用的传统的算法。因为他们那个特别的小样本,然后觉得深度学习的算法还不如传统的算法可靠。所以在深度学习类算法中,如何提高深度学习算法的可解释性?那一代的参数最终都隐含着什么?换一个数据,这些参数是不是稳定,都是一个值得探究和思考的问题,谢谢。
朱鹏飞:谢谢。好的,那我稍微讲解一下。目前的话虽然说我们现在有大规模的数据,然后还有深度学习的环境感知方面模型的一个爆发,也一直在刷榜。但现在其实受限于环境能力,它也是环境感知能力的一个天花板。我们在未来的这个研究里边,面对决策安全性的问题。根据各位专家的建议,我们应该把环境感知和决策联合起来。然后的话去建立这种感知和决策一体化的一些学习的模型,从这个角度来讲,去提升这个决策的安全性。这个是我们对各位专家观点的一个小结。本来我们把这个相关的问题放到最后一个,我把它往前提一提,然后我们把它展开一点,关于这个智能系统的这一块的话,然后它是一个典型的一个交叉学科。我们在前两周有一个天津市机器学习重点实验室的年会。我们也对我们实验室在无人机环境感知方面的工作做了一个汇报。汇报完之后的话,学术委员会的专家都提了一个意见,非常一致。说第一个的话看不到实物。我们做的这个还是典型的视频分析,虽然说我们是做无人机的对比,感觉还是典型的视频分析。那专家的话就建议我们,能跟控制学科,还有其他学科的人合作,去做一些交叉学科的东西。然后在这里面我们这也引申出一个问题。环境感知目前来讲的话,它主要是侧重于依赖视觉传感器、激光雷达,其实包括这个IMU、GPS等等,做一些对环境的理解。那怎么样才能把这个环境感知跟决策控制、相关学科结合,然后能够做一些交叉研究。然后我们能够真正的把这个视觉算法的这个研究和迭代,跟角色、控制这些合在一起,这个的话我从这个角度来讲,我们能否更好的去加快这个领域的一个发展。这是我们本来放到最后一个问题,我们把它提到前面讨论。这个因为咱们今天有工业界的,有学术界的,我们也想在这个地方引起一些争鸣。好,那请各位专家表达自己的观点。
吴冲:其实现在应该提的这个就感知决策控制一体化的这么一个概念在无人机方向上现在有一些探索的,就实际上是会拿这个深度强化学习。直接做一个端到端的这种处理。就可能我输入的一个视频图像或者一些原始数据,那么输出直接飞行控制的一些控制量控制指令。这个是现在我们也在做的一些尝试的事情。但这个其实背后的一个点,就像刚才王老师说的,可能他的这种稳定性和可解释性现在确实会是一个问题点。但是我觉得这个大的思路方向还是可以的。去把感知和控制和决策做一些耦合,就不一定是这种基于深度强化学习完全的端到端的一个方案,可能一些这种耦合的、反馈闭环的、交叉的方案,我觉得应该还是有一些可能性的。而且这种场景可能他应对复杂的环境的能力会强一些。但是反过来讲,就可能我们现在了解的他对于这种训练场景的要求会特别高。可能不会像我们现在做一个研究是说控制只做控制动力学建模。那么感知做这个它会是一个更耦合,对于这种训练场景要求更高的一个门槛吧。
薛建儒:其实对这个传统的环境感知和自主系统的环境感知,它的区别在哪里。实际上我们大家都习惯了选一个点来开展研究。尤其我们在这个学校里面做研究的这个团队,包括对这个障碍物物体的识别检测、跟踪以及对他的未来的轨迹预测,这都是单点的一个研究。那么这些单点的研究,它对问题的边界都已经定义的非常清楚了,比如我们构建了很多的数据集。那么这个数据集实际上就一定对这个单点的问题,它做了一个界定。但对于这个自主智能系统来讲的话,他的感知是和要完成的任务是有关系的。比如说我们这个自主系统到底要做什么?我们要用什么样的任务或者什么样的一个场景。在什么样的场景下完成这个任务,去体现它的自主性。它实际上是一个系统性的。在这里面,要对这个环境感知的这个环节,要对这个系统性能,从系统的角度对它进行分解,来界定我们的环境感知应该具备什么样的一个能力。那么在这种系统性能导引下,分解到环境感知里面的边界它往往和我们数据集里面训练的这种所做的这个环境感知问题有很大的一个差异,所以这是我觉得是传统的环境感知和自主智能系统环境感知最大的一个区别。我们定义问题的前期条件已经发生了变化。比如说对于一些这个弱小目标的检测识别。在我们的环境感知里面,传统环境感知里可能非常困难,尤其是远处的、小的这些数据的检测识别。但是对自主智能系统来讲的话,如果这些问题,这些感知的这些目标区域,它不影响任务,那么这些问题反倒它并不重要。所以我想这是这个自主智能系统,它的环境感知和传统的环境感知这个问题的最大的一个区别。当然怎么来做好从感知到控制整个的一体化这个问题。因为这个里面讨论非常多,我们讲端对端的学习实际上是想解决这个问题。但是端对端中间的黑箱,我们的映射、模型,它能够覆盖的这个范围都非常困难,因为如果每一个点问题都是一个空间的话,那么这个端对端的问题空间应该是一个指数级的增长的问题,所以这就导致我们现在无论是用深度强化学习,还是现有的这个深度学习去解决这个问题的时候,它不稳定且它的可解释性比较差。我想这是问题本身所决定的。
王栋:我觉得感知控制决策一体化。要想说实现有一个阶段性的步骤,需要我们做视觉的人,做控制的人,甚至公司,甚至有产业背景的人,针对某一个具体的问题,要搭一个大场景的仿真环境。然后我自己在一直想着我们做跟踪的问题,像做跟踪的问题它拍摄的视频始终是有限的,而且拍这个视频难免要带着一些主观性。比如你要跟踪一个车,你就尽可能的会拍一些那个车,但是和我们真实场景中的那个gap 就会比较大。
然后我自己也是绝地求生那个游戏的粉丝。我就有时候就在想,说我们如果把那个游戏场景中的每一个小人都能给他精准的跟踪起来,知道这个小人进这个房子了,他有可能从哪儿出来,然后把那些出来的地方都锁定。那我们就可能形成一个真正的实景,就和实际中的一些跟踪就非常接近。但这个这种数据是就没法采集的,而且很难采集实景数据。所以可能大规模的这种和实景越gap越小的仿真环境,可能是一个思路。这也可能会衍生另外一个问题,你这个仿真环境到底和实际场景的gap 有多大,怎么去以更小的代价来缩小这个gap。我觉得可能是一个比较有意思的一个方向吧,谢谢。
朱鹏飞:好,这个问题来讲的话,确实这个问题太大了。因为面向这个智能系统的话,它确实是多个学科交叉的。在这里边的话,今天我们各个专家也分享了自己的观点。首先我觉得薛老师这个观点非常好,我这种自主智能系统它的一个环境感知一定是面向系统。所以我们应该从系统任务自上而下的进行拆解。对这个智能系统的环境感知的话,有一个边界,这个是第一个观点。第二个观点是我们想做到感知决策控制一体化的话,目前如果说我们采用这种端到端的模型,它的可解释性难以保证。另外这个整个空间会发生爆炸。这样的话从目前可行的角度来讲,还是可以从多阶段的这样一个角度,去完成这个任务。最后一个观点这个大场景的话,针对真实场景和虚拟场景,他们之间的一个gap ,包括我们采集的这些数据。限定场景它的一个gap 的问题。在这里边然后融入仿真环境和我们这个采数据采集这样建立一个平台,结合去解决实际的问题。这也是一个可以追求的解决途径。对于这个问题的话,我们相信还会有更多的观点和答案。我们可以把它放在这个未来的讨论里面。这个问题我们讨论完之后的话,然后我们再引申出来下一个环节,刚才薛老师提到面向系统,韩军伟老师的报告里面最后也提到,他对可见光做完之后,他要考虑SAR图像,考虑其他的场景。那在这里边的话这两年大规模的预训练模型,然后已经风靡各个领域了。那对于这个视觉领域里面来讲的话,然后也开始去训练自己的这个大规模预训练模型。那对于智能系统的环境感知来讲,第一个是我们是否有必要去训练自己的这个大规模的训练模型。第二的话如果有必要,我们应该怎么去发展。然后针对我们这个智能系统,环境感知这个领域里边的这个大规模训练模型。请各位专家分享观点。
夏桂松:因为最近我们的确是在用视觉和语言的这个预训练的大模型做了一些open set of recognition 或者zero shot segmentation 感觉很好用。但是在自然场景下确实可以做这个事情。就像刚才韩老师说的,其实我做的比较多的一个应用遥感场景。在遥感的时候,我们也希望做这种大规模的预训练模型。因为现在视觉这个大规模预训练模型我们是用不了的。因为他的语言视觉的这种模式是主要是描述自然场景。
比方说我们遥感场景,他这些语音信息跟遥感的结合不是很紧,不能够直接用。我们现在也在考虑,比如说能不能训练一个大规模的遥感的预训练的模型。因为我们前期也准备了,所有的数据汇聚在一起,可能有千万级别的数据。武汉大学我们也在做这个事情,但是怎么样把这个大规模训练模型训练好。特别是比如说我们想把语义的信息也放进来,这个目前我们觉得还是比较难,而且没有太好的进展,做了一些相关的工作。但是目前的测试效果也不是很好,不是很明显,至少没有达到我们预期的效果。我自己对这个大规模预训练模型,比如说我们现在用的什么clip 这种模型是吧?它这个语义描述都是在图像这个层次。比如说给一个图像,你可以到网上去搜索很多对应的语义,你可以搜索很多图像,然后可以把这个模型给训练出来。但是我们在做语义分割的时候。你的视觉图像的预训练模型语义是在图像这个层次的,但是我们想要的可能比如说对每个像素给他打上一个标签。这两个东西它不是在一个层次上面对吧?这个要用好,可能也不是那么容易。可能也要做一些,比如说我能不能把这两个过程可以解耦是吧?我像素的先把它分成区域,然后再跟预训练模型结合。那在发展这个大规模预训练模型的时候,是不是也可以往那方面考虑。不说我们不仅仅做图像这个层次的大规模的预训练模型,然后还可以做各个不同的理解,或者是认知层次的这种预训练模型是不是都可以做。我们在遥感里面有这样想过,但是这个感觉做起来有一些困难。如果大家有相关的经验,也可以跟我们来分享。
薛建儒:好,朱老师。我补充两句,根据这个夏老师刚才讲的,当然比较具体了。我觉得这个大规模模型,它实际上是深度学习发展到现在的一个必然的一个阶段。因为我们讲这个深度学习,它主要是数据,算力和这个模型算法。那么大模型它从本质上来讲,还是按照这三个因素去的。当然这是第一个它的技术发展,到了目前这样的一个程度了,而且它表现出来非常强能力。也就说我们这个小的模型是没法比的。当然有没有一个通用的适合于各个领域的大规模的模型,我觉得目前看起来还不存在。对各个行业各个领域来讲,目前仍然有去发展这个超大规模模型的必要性。但最终是不是有能够形成超大规模的一个通用的模型,这仍然是个大家还在争论的问题。那么从学术研究的角度来讲,我觉得这个超大规模模型对于高校,对于研究学术界来讲,它实际上是一种阻碍的作用。因为它建立起了一个门槛,这个超大规模的模型,它的这个成本非常高,不是一个小的课题组能够建立起来的。那么这有点像个人计算机和超级计算机,它的发展其实大家可以借鉴一下。那么个人的计算能力和这个超级计算机,尤其我们现在讲的超算,也不是每一个团队都能去做的。所以这个对于超大规模的这个模型,我们在这个研究中应该怎么去考虑他,我们要不要自己构建,还是我们聚焦在其中跟某些平台结合起来,去在里面寻找研究点来做这个超大模型,这是我的个人的一个看法,跟大家一起去探讨一下。
胡清华:这个问题其实最近讨论的也比较多,国内陆陆续续的发布了一系列的大规模的模型。现在对于我们属于高校的这些研究工作者,属于个体户。对于这种个体户来讲,没有资源去参与这方面的这种机会。我觉得其实应该说不同的算法,不同的模型它都有自己的特定的一些应用的一些场景。这个超大规模模型,我们用超量的数据来训练。但是其实他在有些场景下,也不见得工作性能就会非常的好。我们在之前其实也做过一些测试。比如说我们在语音这个方向上,我们天大的这个语音团队之前做过一些识别的算法。这个相对而言它其实并没有用到特别大的一个模型和特别多的数据,发现他们训练出来这个模型跟我们国内几个非常大的团队所做出来的效果甚至会要更好一些。尤其是在一些特定的一些语言。比如说我们其实有一些很小的这种应用场景的这种语言,但是它也价值非常重要。虽然我们可能用一些大规模的数据来训练,出来的模型反而在这方面不见得有好的效果。类似的,我们有研究特定的一些应用场景和我们自己设定的研究目标。我觉得在我们自己所做的这种有特色的工作上,也许会比超大规模模型会有更好的一些效果。当然我们也可以把我们的模型和超大规模的模型去做结合。他适合做他们的事情,我适合做我们的事情,融合起来去解决一些更复杂的一些任务。这个不排斥,但是这个我们也不灰心,不是说有了大规模模型之后,我们做的工作就毫无价值,应该不是这样的一个情况。
朱鹏飞:好的,那感谢各位老师精彩的观点分享。我们后边的话,还有三四个问题。然后我们针对后边这几个问题的话,我们再进行进一步深入的讨论。今天的这个讨论基本上是层层递进的。我们把这个再精炼一下,然后去再看一下后面的一个问题。接下来的问题,也是薛老师在报告里面提了很多次的一个关键词叫协同。这个协同的话,就我们目前来讲,谈的比较多的是在这个自动驾驶领域里边,这里边有一个车车协同。然后如果说研究多智能体的这个同行的话,它会有多智能体的一个协同。如果说研究这个智能系统,比方说研究遥感,它会有一个空天地一体化的协同。那对于协同感知来讲,第一个是这个缺少大规模的开放平台,这是第一个问题。第二个问题是协同感知它相对于这个单体感知的话,它是有自己的优势,那在这里面究竟它的问题和挑战在什么地方,针对这个协同感知这个地方的话,然后也想请这个各位专家分享一下自己的观点,这个也是作为今天的一个讨论主题。我看薛老师应该是这个掉线了,我再跟他联系一下,先请其他专家分享一下。
夏桂松:我先抛砖引玉说一说,我主要是做遥感的应用多一点。然后的确像朱老师说的我们空天地协同的东西特别多。但是目前这个阶段说我们如果要在整个系统上面,比如说我们天上有卫星无人机,那地面可能有车是吧?各种模态的数据和数据感知的手段。但是目前这个协同可能没有地面,比如说自动驾驶这种协同,那么可能不是实时的。那我们可能更多的是数据之间的这种协同会多一些。比如说卫星拍到的大尺度的这种数据,高分辨率的这种数据和无人机,它在不同角度上面拍这些数据。然后还有地面的街景数据,这不同的数据之间,我们希望都是观察地面,比如说某一个场景,某一个城市,我可能从不同的角度、不同的侧面、不同的时间获取了很多数据。我们希望在数据的处理或者是解析这个层次上面能够协同的。比如说去了解这个城市它的发展状态,这个区域它的发展状态。所以对我们来说,我们更多的是希望能够把不同模态的数据、不同角度的数据、不同时效的数据之间,相关的信息可以挖掘出来,可以找到它中间的这个信息。所以目前来说我们遥感数据处理,或者是理解或者解译里面用的比较多的这种协同,更多的是多模态数据之间的关联分析,数据的挖掘,变化的分析,这些东西会多一点。我们也希望比如说如果我们要处理红外数据,还有刚才像韩老师说的大数据、可见光数据这些数据它的模态完全不一样。那如果能够有更好的,比如说这个有一个大的模型,或者是有一个这个很好的domain adaptation 这些方法或者transfer learning 的方法可能可以把我们的这个协同做的更好一些,我们目前也有很多工作,可以做这个不同模态的数据的融合。
薛建儒:因为协同这件事情实际上是非常重要的。他尤其是我们人类的智能的发展,其实还是体现在由个体到群体的这个协同,比如我们的社会发展,社会组织机构。所以作为这个智能系统来讲,他肯定也朝着这个方向去发展。对于协同来讲,它取决于我们用它要做什么。那么咱们现在讨论的题目是协同感知。也说我们通过这个智能系统之间的这种传感器的交互,然后实现一个更大范围的,更深层次的一个感知。那么在这个任务上来讲的话,应该说他给我们带来了更多的挑战性的问题,包括他们的这个时空对齐,包括我们在更广范围上,更大的尺度上去描述场景的内容,包括它的几何结构,包括它的事件层次等等。所以我觉得这个多车或者多机多智能体,它的协同感知,它可以突破单个智能的局限性。因为单体智能有它的感知范围的局限性。当然我们可以通过其他的手段来给他形成更高更多的输入,超越它当前的传感器的这个覆盖的范围。所以我们说这个多智能体的协同感知带来的这个问题使得我们的研究有更多的学科的增长点,更多挑战性的问题。包括尤其是在对更高层次的职能,因为我们协同的目的最终是要实现群体智能的涌现。也说我们要服务于通过协同实现一加一大于二或者是n 的平方这样的一个智能的涌现。所以这样的话对不同智能体我们通过它们的感知的协同,在群体智能涌现里面,它的作用是非常重要的。我觉得这是很重要的、很好的一个机遇,使得我们能够突破原有的单体智能,包括前面刚才讲到的一些问题。单体智能它里面的感知的不确定性,对决策的影响。那么也可以通过这个协同感知,可以得到一定程度的解决。所以我觉得这个问题它是带来了机遇,同时也给我们带来很多的这个新问题,值得大家去认真的去思考。
胡清华:薛老师讲的非常好,我补充两句。其实我们知道人类社会之所以智能水平这么高的一个非常重要的原因是我们人和人之间构成了一个非常强的连接,形成了社会。我们是不同的人感受到了环境,感受到了这个社会的不同的方面。然后我们可以相互的交流。其实这个交流的过程是一个协同的过程。在这相互的在分享共享信息的一个过程中,不仅在共享信息方面可以协同,而且在后面的决策、控制,对环境的改造上都是可以做协同的。那对于我们目前的这个智能体来讲,单一的智能体存在因为环境、因为个人本身的这个传感器方面的问题带来的各种不确定性。通过协同就可以把这种不确定性消除掉,或者是降低。另外一方面,通过协同可以实现不仅是环境感知,我觉得可能未来非常重要的一个研究方向,这种协同的学习。我们目前的这个深度学习都是单一的一个模型的学习。未来有没有可能提出一种多个深度神经网络的协同学习?比如说我就举一个简单的例子。对无人驾驶的出租车来说,几万辆出租车同时在跑,我们一辆车学一个驾驶模型,我们一万辆车协同起来之后,就类似于把我们的一万个驾驶员的驾驶的技巧、驾驶的经验都给它共享起来,形成一个更好的这样的一个模型。那这样的话他比单个的学习能力就会要强大了很多,对吧?可是现在这方面好像还没有很好的办法来解决这个问题。当然我们有一些简单的,比如说通过用一种加权平均的方式把它融合起来。但这种远远不是我所希望的这种模型,这里边也有很多协同的问题。这个目前包括联邦学习也好,分布式学习也好,还有那些集成的这样一些机制也好,我觉得都可能只是其中的一个初步的尝试。未来这个是社会化的感知,社会化的学习,社会化的决策。这个可能都会极大的提升我们目前的这种智能系统的感知认知,学习决策的能力吧。