

论文题目:Task-Customized Mixture of Adapters for General Image Fusion
作者:朱鹏飞,孙洋(硕士研究生),曹兵,胡清华
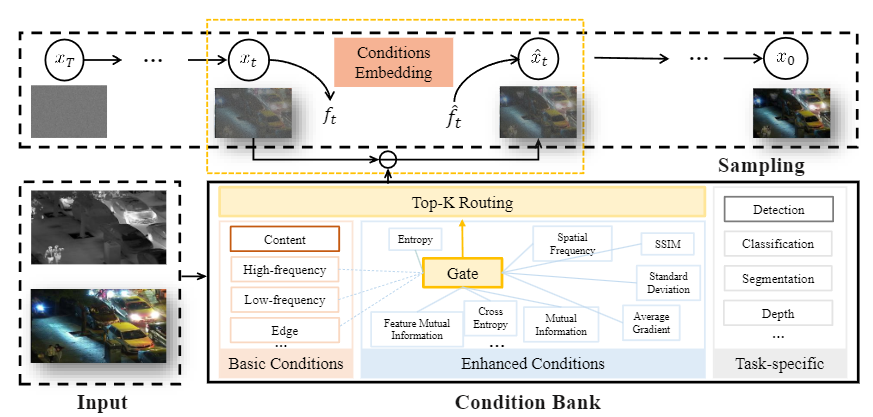
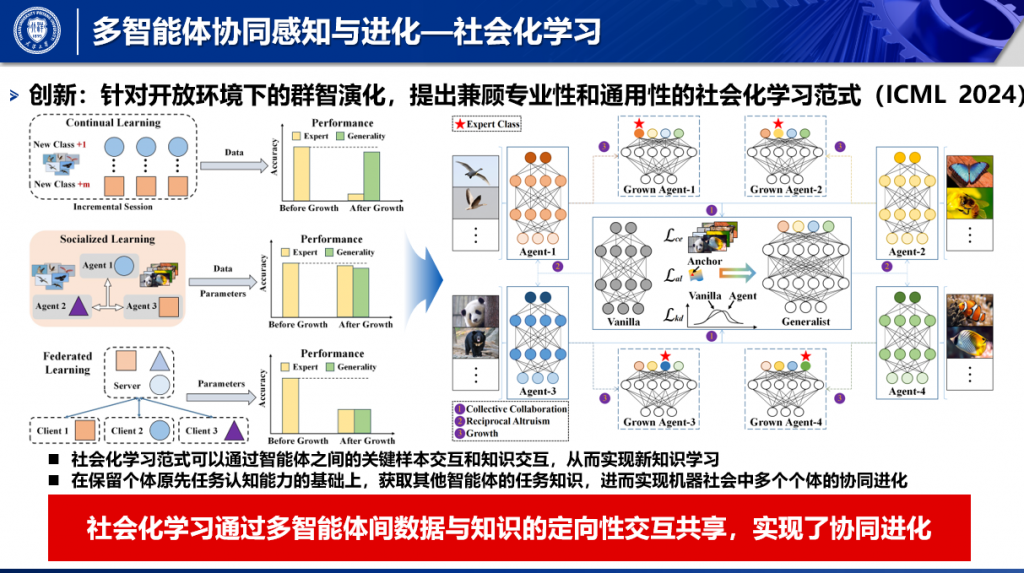
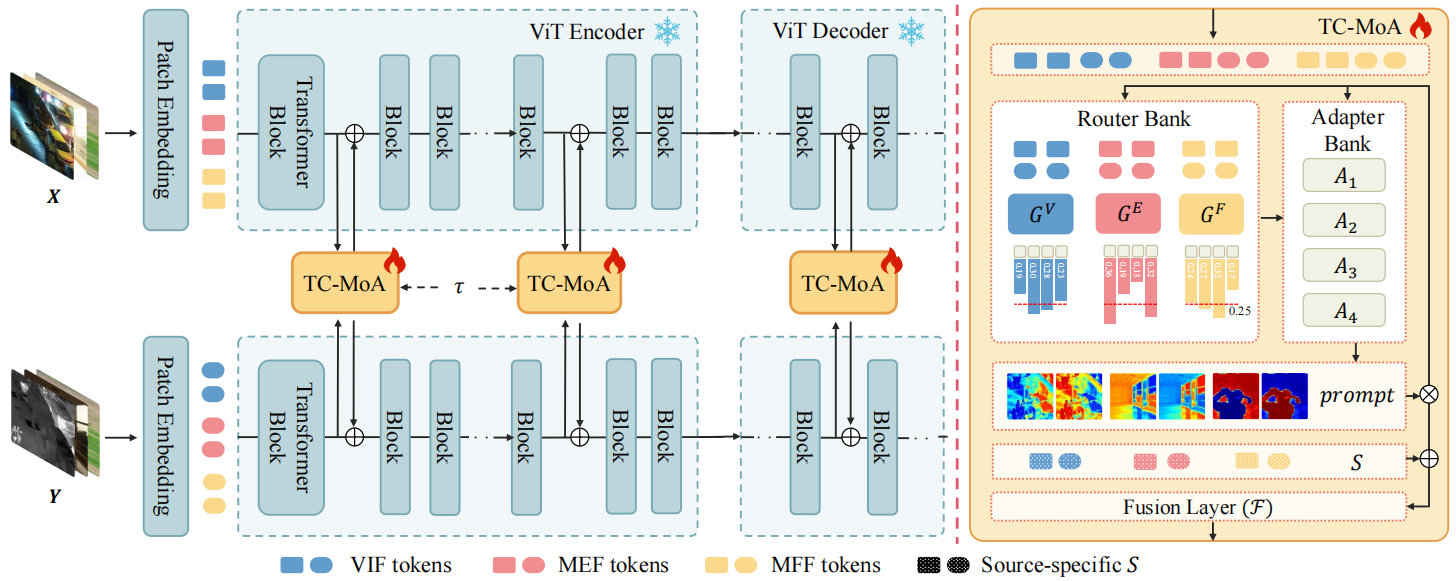
论文概述:通用图像融合旨在整合来自多源图像的重要信息。然而,由于不同融合任务之间存在巨大差距,各自的融合机制在实践中差异很大,导致各子任务之间的性能有限。为了解决这个问题,我们为通用图像融合提出了一种新的任务定制混合Adapters(TC-MoA),在一个统一的模型中自适应地提示各种融合任务。我们借鉴了混合专家(MoE)的设计,高效微调混合Adapters,以提示预先训练好的基础模型。特定任务路由网络会定制这些Adapters的混合,以便从具有动态地从不同源图像中提取特定任务信息,执行自适应视觉特征提示融合。这些Adapters可在不同任务间共享,并受到互信息正则化的约束,从而确保与不同任务的兼容性,同时实现多源图像的互补。值得注意的是,我们的 TC-MoA 可以控制不同融合任务的主导强度偏差,成功地将多个融合任务统一在一个模型中。广泛的实验表明,TC-MoA 在学习共性方面优于其他竞争方法,同时还保留了一般图像融合(多模态、多曝光和多焦点)的兼容性,并在更广泛的实验中表现出惊人的可控性。
论文链接:https://arxiv.org/abs/2403.12494
论文代码:https://github.com/YangSun22/TC-MoA
论文题目:AMU-Tuning: Learning Effective Bias for CLIP-based Few-shot Classification
作者:汤钰炜(硕士研究生),林桢熠(硕士研究生),王旗龙,朱鹏飞,胡清华
论文概述:最近,预训练的视觉-语言模型(如CLIP)在few-shot learning领域显示出了巨大的潜力,吸引了大量的研究关注。虽然人们已经为提高CLIP的few-shot泛化能力做了大量努力,但现有方法有效的关键因素尚未得到充分研究,限制了CLIP在few-shot learning领域的进一步探索。在这篇文章中,我们首次从logit bias的角度,引入了一个统一的公式分析现有的基于CLIP的few-shot learning方法,这促进我们学习一个有效的logit bias来进一步提高基于CLIP的few-shot learning方法的性能。
为此,我们分解了三个涉及logit bias计算的关键组件(即logit特征、logit预测器和logit融合),并在经验上分析了对few-shot分类性能的影响。根据对关键组件的分析,这篇文章提出了一种新的AMU-Tuning方法,学习有效的logit bias来实现基于CLIP的few-shot分类方法。具体来说,我们的AMU-Tuning方法通过利用适当的辅助特征来预测logit偏差,这些特征被输入一个高效的特征初始化线性分类器,该分类器使用多分支训练。最后,开发了一种基于不确定性的融合方法,将logit bias引入到CLIP中,用于few-shot分类。实验是在几个广泛使用的基准上进行的,结果表明我们提出的AMU-Tuning明显优于同类方法的性能,同时在没有额外技巧的条件下实现了最先进的性能。
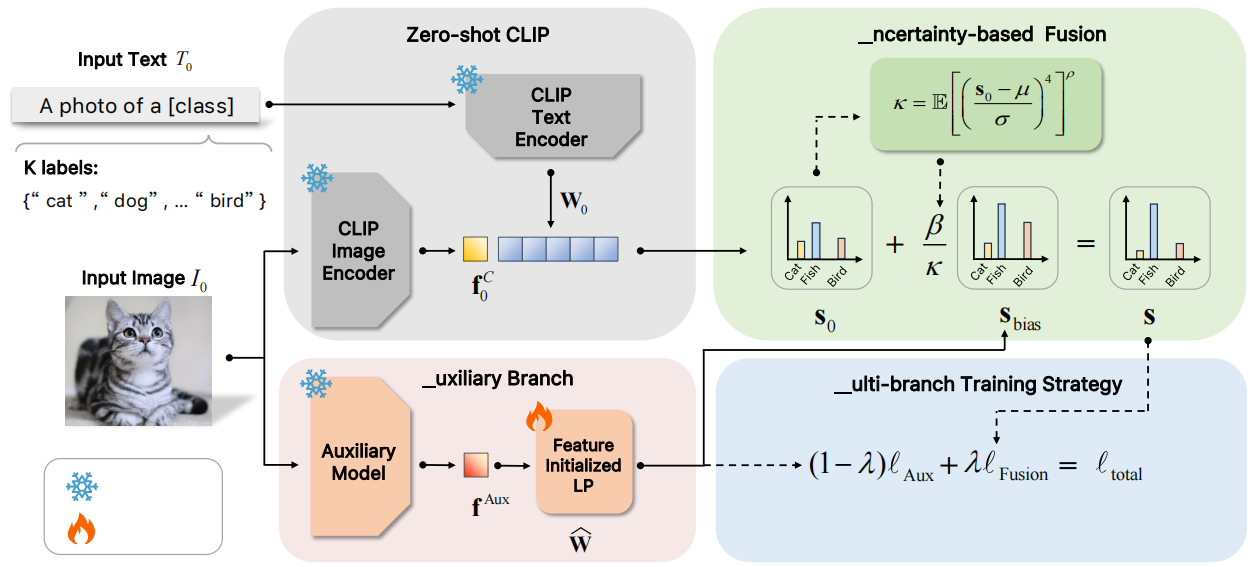
论文链接:https://openaccess.thecvf.com/content/CVPR2024/papers/Tang_AMU-Tuning_Effective_Logit_Bias_for_CLIP-based_Few-shot_Learning_CVPR_2024_paper.pdf
论文代码:https://github.com/TJU-sjyj/AMU-Tuning
论文题目:Every Node is Different: Dynamically Fusing Self-Supervised Tasks for Attributed Graph Clustering
作者:朱鹏飞,王倩(硕士研究生),王煜,李佳璐,胡清华
论文概述:属性图聚类是一种无监督的任务,它将节点划分为不同的簇。自监督学习在处理这一任务方面显示出了巨大的潜力,最近的一些研究同时学习多个自监督任务,进一步提高了性能。目前,不同的自监督任务为所有节点分配相同的权重集合。然而,论文中观察到一些相邻处于不同簇的节点对不同的自监督任务需要显著不同的权重。为了解决这个问题,该论文设计了一种新颖的图聚类方法,即动态融合自监督学习。该方法使用来自门控网络的不同权重来融合从不同的自监督任务中提取的特征,并且提出了一种包含伪标签和图结构的双层自监督策略以有效地学习门控网络。充分的实验结果也证明了论文所提出方法的有效性。
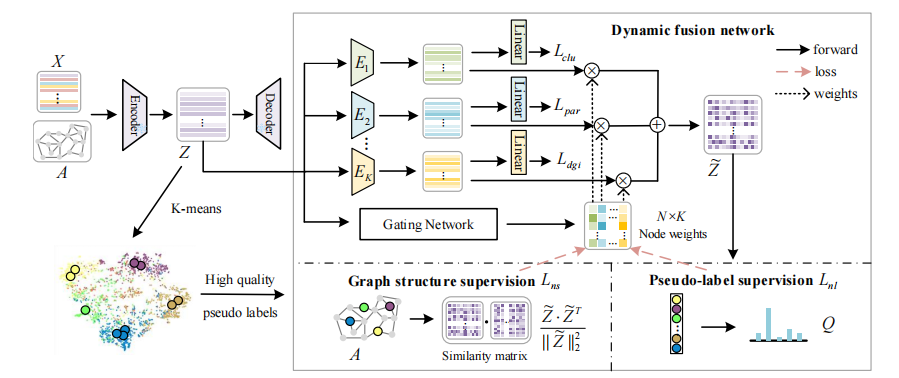
论文链接:https://ojs.aaai.org/index.php/AAAI/article/view/29664
论文代码:https://github.com/q086/DyFSS
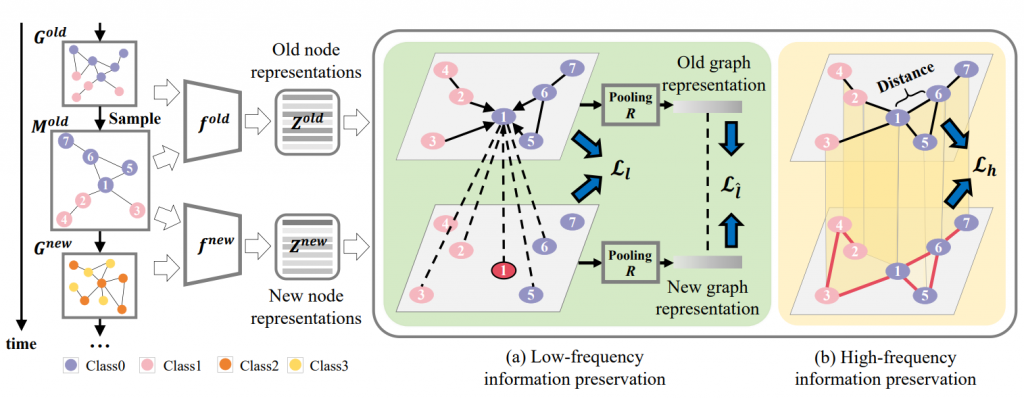
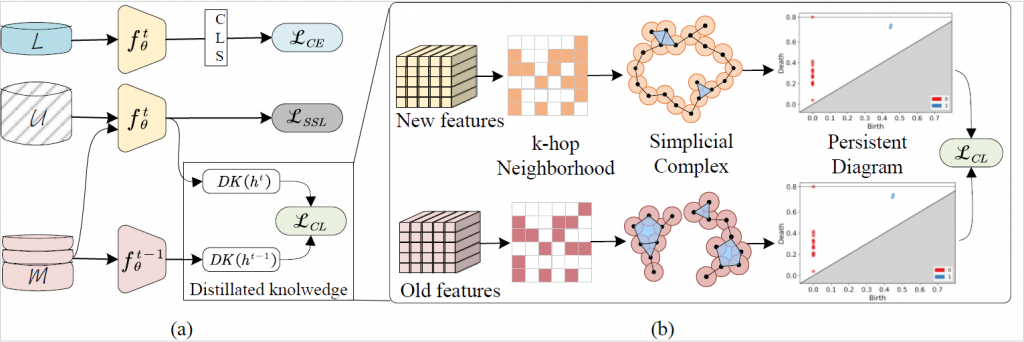
论文题目: Dynamic Sub-graph Distillation for Robust Semi-supervised Continual Learning
作者:范妍(博士研究生),王煜,朱鹏飞,胡清华
论文概述: 连续学习策略通常需要大量的标记样本,限制了其在实际场景中的应用。在该论文中,我们提出利用数据的结构稳定性实现半监督连续学习(SSCL),即模型持续地学习新的标记受限的数据。我们分析并证明了未标记数据的不可靠分布会导致连续学习的不稳定, 并且无标记数据的遗忘问题没有得到解决, 该问题严重影响了SSCL的学习性能。为解决这一问题,我们提出了一种动态子图蒸馏(Dynamic Sub-graph Distillation, DSGD)的半监督持续学习方法,通过利用语义和结构信息在无标记数据上实现更稳定的知识蒸馏。首先,我们形式化定义了通用结构蒸馏模型,并为持续学习过程设计了动态图的构造方法。接下来,我们提出结构化的蒸馏向量,并设计了一种动态的子图蒸馏算法,从而实现了端到端的训练,能够适应不同尺度的任务扩展。最后,我们在三个数据集 CIFAR10、CIFAR100 和 ImageNet-100 上以不同的监督比例进行了实验。实验结果证明了我们的方法对无标记数据分布偏差的鲁棒性,并且在目前最新技术的基础上实现了性能的显著提升。
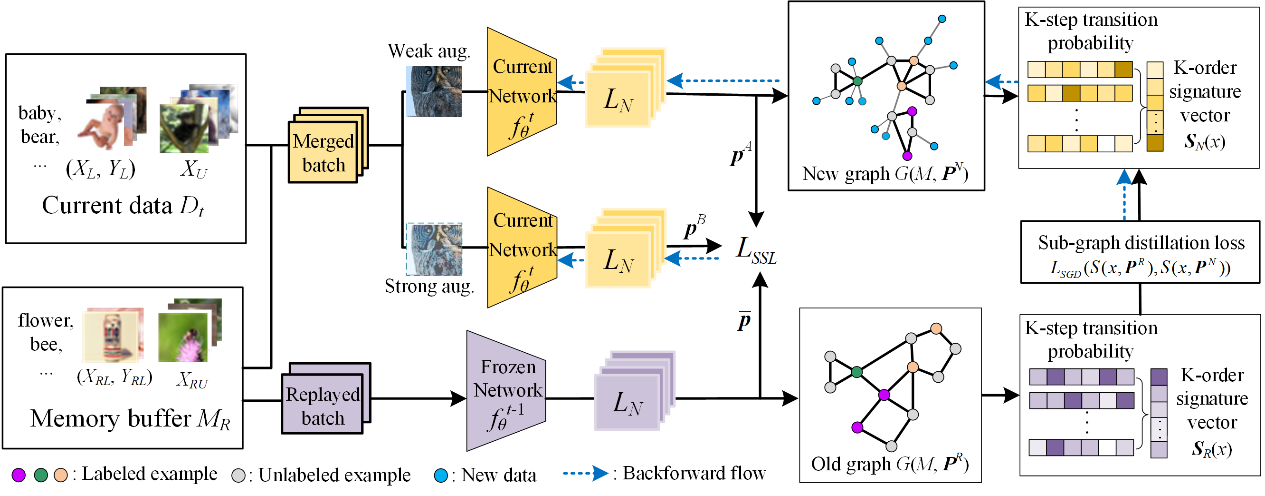
论文链接:https://ojs.aaai.org/index.php/AAAI/article/view/29079
论文代码:https://github.com/fanyan0411/DSGD
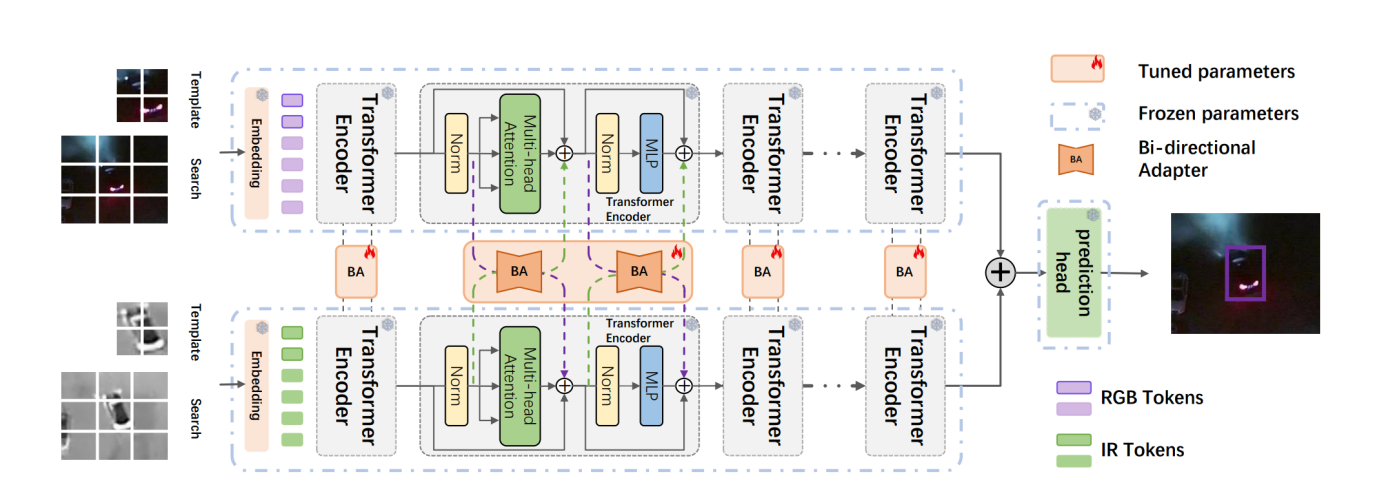
论文题目:Bi-directional Adapter for Multimodal Tracking
作者:曹兵,郭俊良(硕士研究生),朱鹏飞,胡清华
论文概述:由于计算机视觉的快速发展,单模态(RGB)目标跟踪近年来取得了重大进展。考虑到单一成像传感器的局限性,引入多模态图像(RGB、红外等)来弥补这一缺陷,以实现复杂环境下全天候目标跟踪。然而,当主导模态在开放场景下动态变化时难以获取充分的多模态跟踪数据,现有技术大多无法动态提取多模态互补信息,导致跟踪性能不理想。为了解决这一问题,我们提出了一种基于通用双向adapter的多模态视觉提示跟踪模型,实现多模态相互交叉提示。我们的模型由一个通用的双向adapter和共享参数的特定于模态的transformer编码器分支组成。编码器使用冻结的预训练的基础模型权重分别提取每个模态的特征。我们开发了一种简单而有效的轻量级adapter,将特定于模态的信息从一种模态转移到另一种模态,以自适应的方式执行视觉特征提示融合。通过添加更少(0.32M)的可训练参数,我们的模型与全微调方法和基于提示学习的方法相比获得了更好的跟踪性能。
论文链接:https://ojs.aaai.org/index.php/AAAI/article/view/27852
论文代码:https://github.com/SparkTempest/BAT
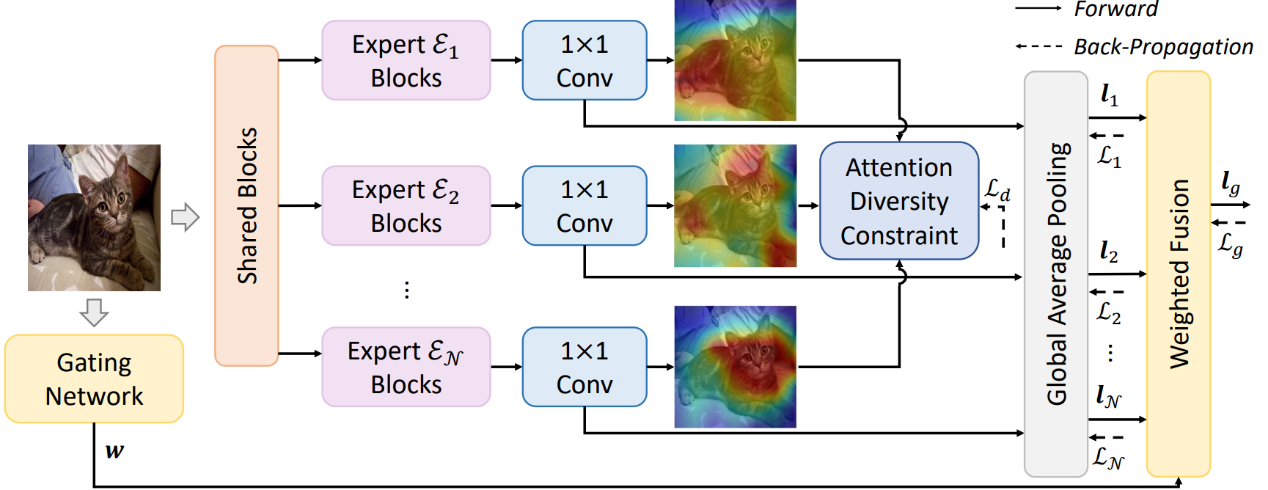
论文题目:Exploring Diverse Representations for Open Set Recognition
作者:王煜,穆郡贤(硕士研究生),朱鹏飞,胡清华
论文概述:开放集识别任务要求模型对属于已知类的样本进行分类,同时在测试过程中拒绝未知样本。目前,生成模型在该任务中的表现通常优于判别模型,但最近的研究表明,生成模型在复杂任务上计算上不可行或性能不稳定。在本文中,作者深入分析了该任务,并发现学习补充表示在理论上可以降低开放空间风险。在此基础上,提出了多专家多样化注意力融合模型。该判别式模型由多个学习不同表示的专家组成,这些专家通过注意多样性正则化模块来学习,以确保注意图是相互不同的。每个专家的预测进行自适应融合,并通过打分函数拒绝未知样本。标准和大规模开放集识别任务上的大量实验结果表明,该方法在AUROC上的性能优于现有的生成模型高达9.5%,且计算成本较低。该方法还可以无缝地融合到现有的分类模型中。
论文链接:https://ojs.aaai.org/index.php/AAAI/article/view/28385
论文代码:https://github.com/Vanixxz/MEDAF
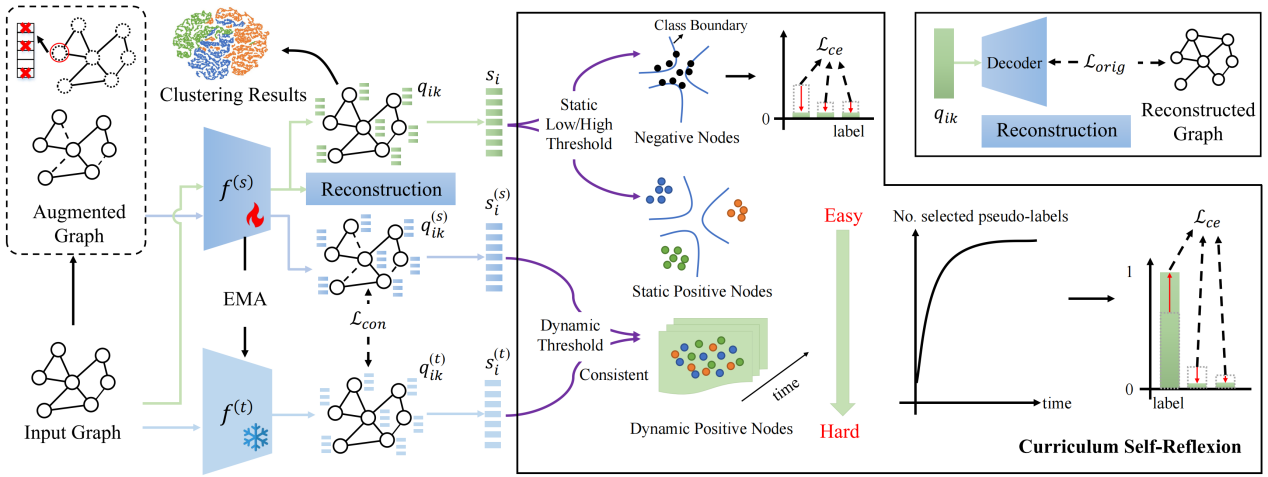
论文题目:Boosting Pseudo Labeling with Curriculum Self-Reflexion for Attributed Graph Clustering
作者:朱鹏飞,李佳璐(博士研究生),王煜,肖斌,张敬林,林婉瑜,胡清华
论文概述:属性图聚类是一种无监督学习任务,旨在将图的各个节点划分为不同的组。现有方法侧重于设计各种借口任务来获得合适的监督信息进行表征学习,其中预测式方法显示出很大的潜力。然而,这些方法(1)会产生对聚类目标的辅助任务偏差;(2)由于静态阈值的设置而引入标签噪声。为了解决这个问题,我们提出了一种新的自监督学习方法,即基于课程自我反思的伪标签设计方法(PLCSR),该方法通过挖掘模型自身信息来学习可靠的伪标签,以自我反思的方式实现节点的渐进式处理。首先,利用原始编码器参数的指数移动平均构造自辅助编码器来代替辅助任务,这为寻找高置信度伪标签提供了额外的视角。其次,设计了一种基于动态阈值的课程选择策略,以更准确地充分利用图节点。除了在初始阶段选择的高置信度简单节点外,还为两个编码器产生一致预测的困难节点分配伪标签,以避免欠学习问题。对于其他高不确定的困难节点,模型不做判断以尽量减少对优化的不利影响。大量实验表明,PLCSR显著优于最先进的预测式方法CDRS,在聚类准确率方面提高了6%以上。
论文链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10669618
论文代码:https://github.com/Jillian555/PLCSR
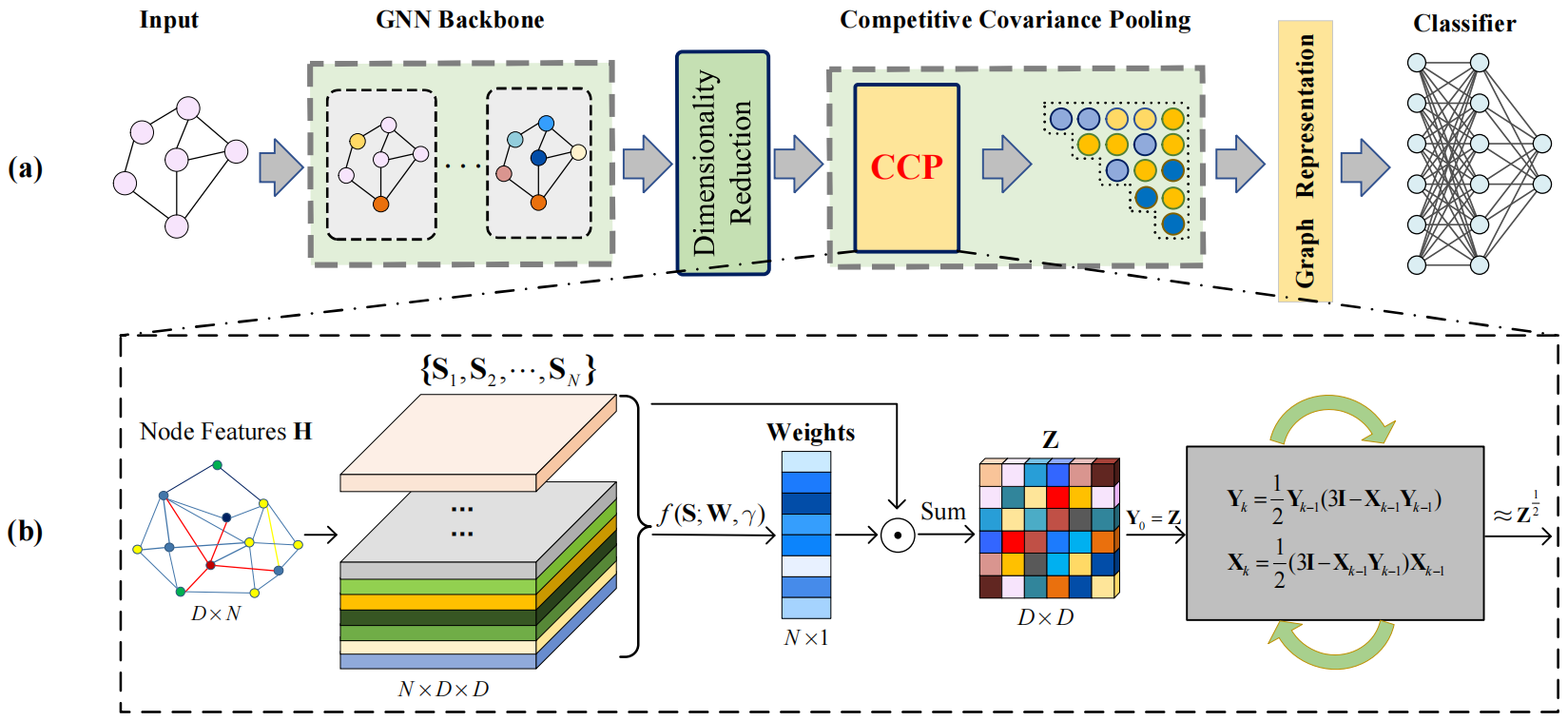
论文题目:CCP-GNN: Competitive Covariance Pooling for Improving Graph Neural Networks
作者:朱鹏飞,李佳璐(博士研究生),董喆,胡清华,王啸,王旗龙
论文概述:图神经网络(GNNs)在图分类任务上取得了一定进展,其中通过汇总节点特征来生成图表示的全局池化对最终性能起着关键作用。现有的GNNs大多采用全局平均池化或其变体构建,没有充分考虑节点特异性,忽略了节点特征固有的丰富统计特性,限制了GNNs的分类性能。因此,本文提出了一种基于图结构的竞争协方差池化(CCP)算法,即图通常由节点集的关键部分识别。首先,CCP生成节点的二阶表示以探索节点特征中固有的丰富统计信息,将其输入基于竞争的注意力模块,通过学习节点权重有效发现关键节点。随后,CCP通过求和将节点级二阶表示与节点权重结合起来,为每个图产生协方差表示,同时引入迭代矩阵归一化来考虑协方差的几何形状。CCP可以与各种GNNs(即CCP-GNN)灵活集成,以很少的计算成本提高了图分类任务的性能,在7个图级基准数据集上的实验结果表明,CCP-GNN的性能优于或可与现有技术相媲美。
论文链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10509794
论文代码:https://github.com/Jillian555/CCP-GNN













