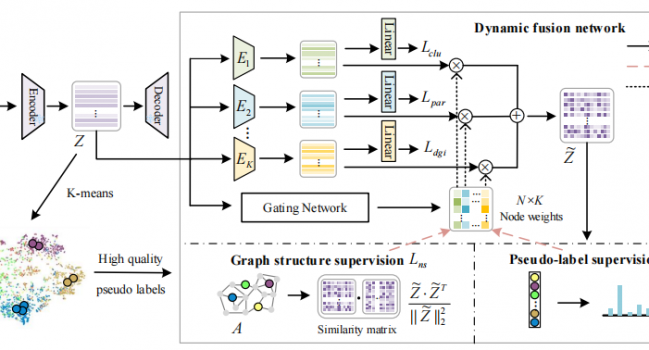
论文《Boosting Pseudo Labeling with Curriculum Self-Reflexion for Attributed Graph Clustering》被TNNLS录用
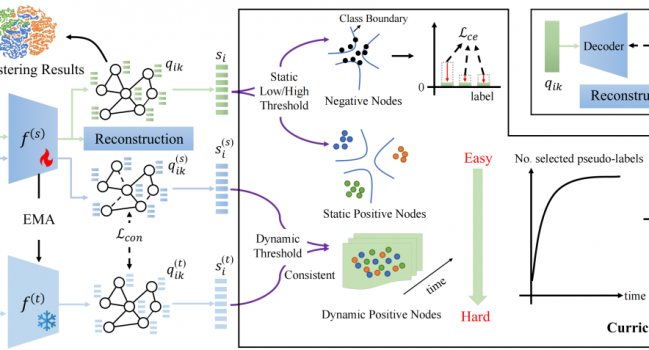
论文题目:Boosting Pseudo Labeling with Curriculum Self …
论文《Socialized Learning: Making Each Other Better Through Multi-Agent Collaboration》被ICML录用
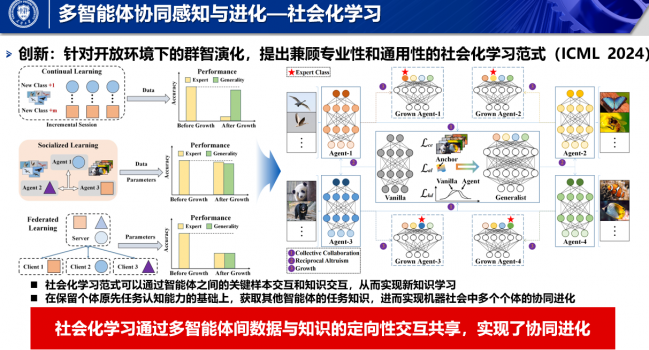
论文题目:Socialized Learning: Making Each Other Better …
论文《CCP-GNN: Competitive Covariance Pooling for Improving Graph Neural Networks》被TNNLS录用
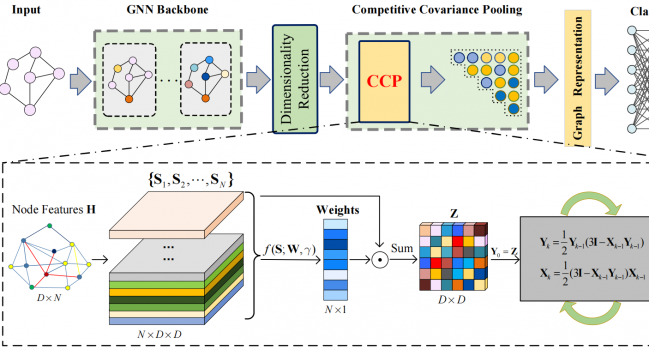
论文题目:CCP-GNN: Competitive Covariance Pooling for I …
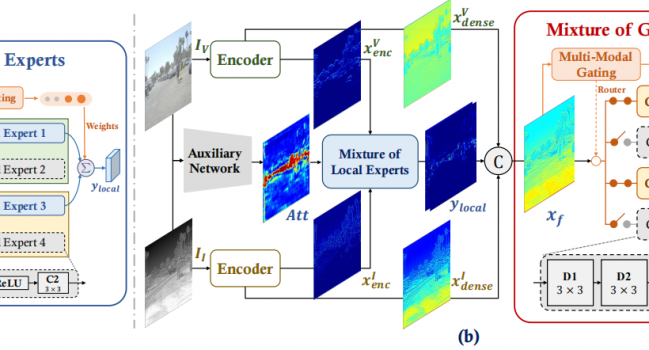
论文《Dynamic Brightness Adaptation for Robust Multi-modal Image Fusion》被IJCAI24录用
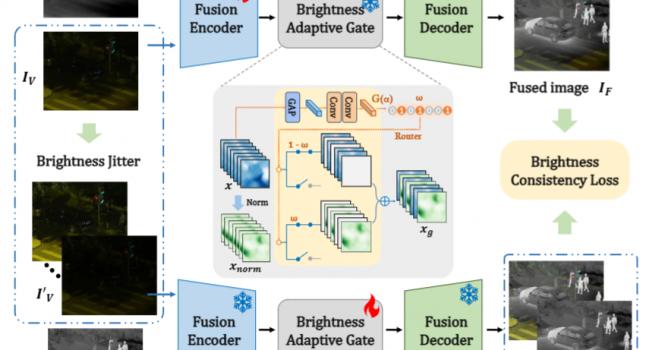
论文题目:Dynamic Brightness Adaptation for Robust Mult …
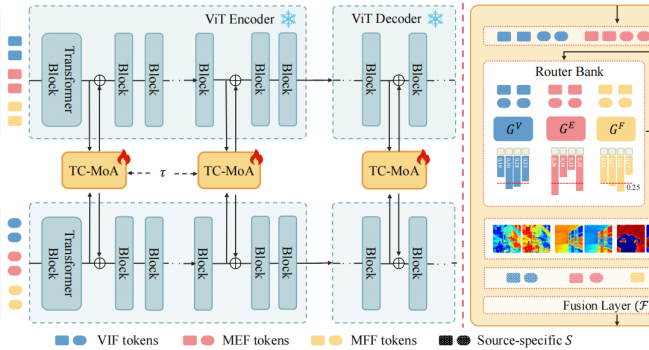







论文《Cross-Drone Transformer Network for Robust Single Object Tracking》 被IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY录用
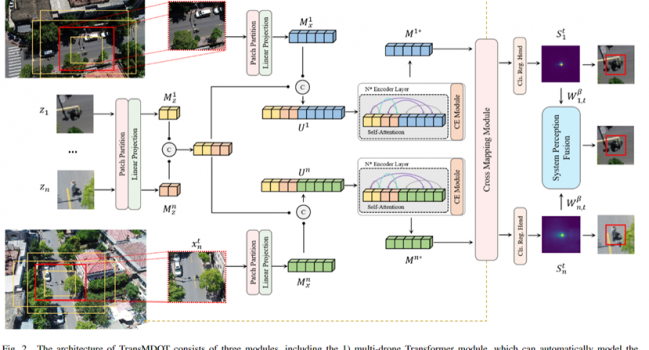
1. 摘要 无人机已被广泛用于各种应用,如空中摄影和军事安全,因为与固定摄像机相比,无人机具有高机动 …

论文《Autoencoder-based Collaborative Attention GAN for Multi-model Image Synthesis》 被IEEE TRANSACTIONS ON MULTIMEDIA录用
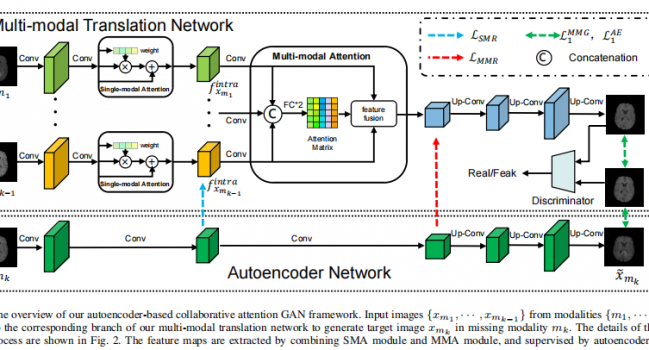
1. 摘要 从临床诊断到公共安全,各种实际场景都需要多模态图像。然而,由于成像条件的限制,某些模态可 …
论文《OpenMix+: Revisiting Data Augmentation for Open Set Recognition》 被IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY录用
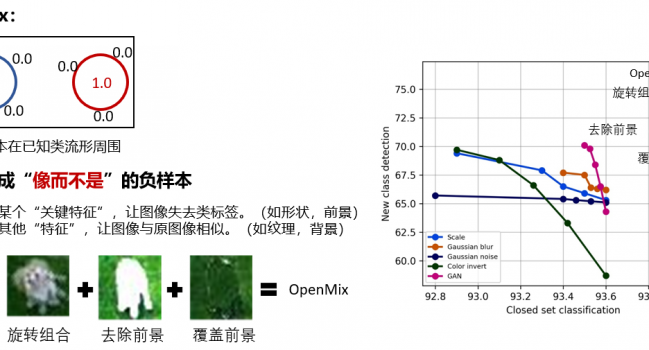
1. 摘要 开放环境中包含已知类样本和大量的未知新类样本。开放集识别要求分类器不仅可以对已知类样本进 …
论文《Multi-Task Credible Pseudo-Label Learning for Semi-supervised Crowd Counting》被IEEE Transactions on Neural Networks and Learning Systems录用
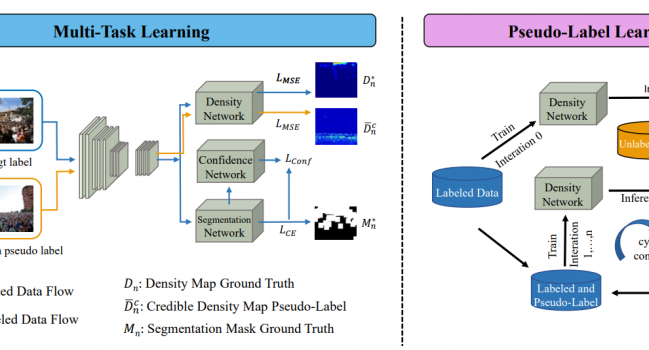
1.1 引言 自训练作为一种广泛使用的半监督学习策略,产生的伪标签缓解了人群计数中标注耗时费力的问题 …
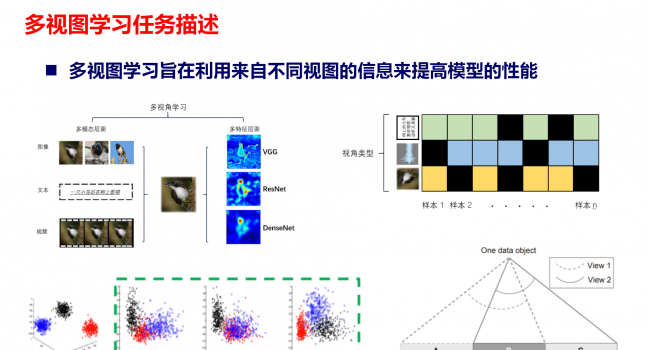
论文《Multi-view Knowledge Ensemble with Frequency Consistency for Cross-Domain Face Translation》被IEEE Transactions on Neural Networks and Learning Systems录用
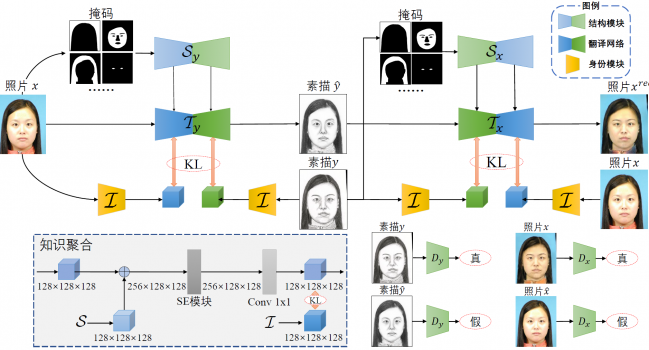
1.1 引言 多视图学习的目的是联合使用来自不同视图的信息,这些视图可能捕获于多个来源或不同的特征子 …
论文《Robust Multi-Drone Multi-Target Tracking to Resolve Target Occlusion: A Benchmark》被IEEE Transactions on Multimedia录用
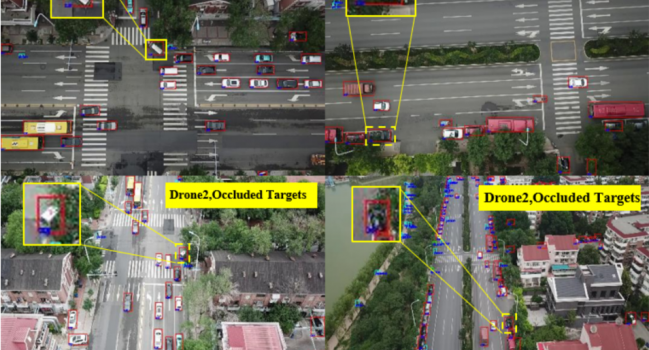
1 引言 多无人机多目标追踪是协同环境感知领域重要的研究方向,其目的是实现多视角信息融合,克服单架无 …

论文《DetFusion: A Detection-driven Infrared and Visible Image Fusion Network》被 ACM MM 2022 录用

论文下载与视频链接: https://dl.acm.org/doi/10.1145/3503161. …