论文下载与视频链接: https://dl.acm.org/doi/10.1145/3503161.3547902
代码链接:https://github.com/SunYM2020/DetFusion
红外和可见光图像融合旨在利用两种模态之间的互补信息来合成包含更丰富信息的新图像。大多数现有的工作集中在如何更好地融合两个模态的对比度和纹理方面的像素级细节,但忽略了图像融合任务旨在更好地服务于下游任务。对于目标检测这一典型下游任务,图像中的目标相关信息通常比仅关注图像的像素级细节更有价值。
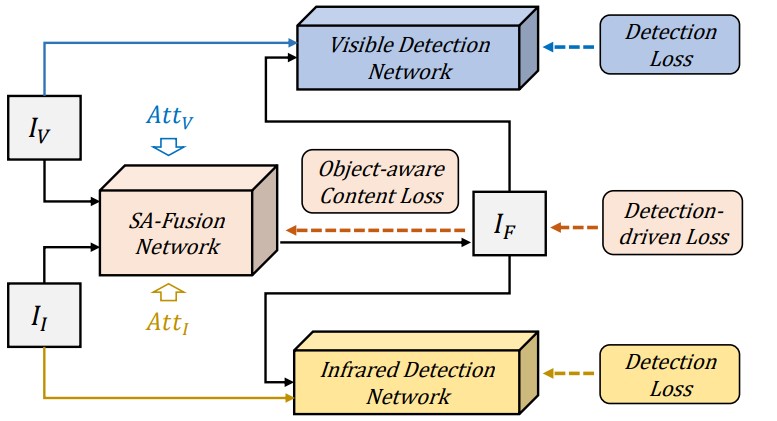
本文提出了一种检测驱动的红外和可见光图像融合网络(DetFusion),它利用在目标检测网络中学习到的目标相关信息来指导多模态图像融合。我们将图像融合网络与两种模态的检测网络级联,并使用融合图像的检测损失来为图像融合网络的优化提供任务相关信息的指导。考虑到目标位置为图像融合提供了先验信息,我们提出了一种基于目标感知的内容损失函数,该内容损失函数激励融合模型更好地学习红外和可见图像中的像素级信息。此外,我们设计了一个共享注意力模块,以激励融合网络从目标检测网络中学习目标特定信息。
研究动机
诸如救灾和交通管理之类的实际应用需要能够处理全天时工作的目标检测算法。然而,在低光照条件下,基于可见光图像的目标检测的性能受到影响,尽管红外成像对光照变化具有鲁棒性,但它缺乏重要的纹理细节信息。考虑到红外和可见光图像的融合可以弥补单一模态的缺陷,基于融合图像的目标检测可以很好地满足实际应用中全天工作的需要。
目标检测的目标是找到图像中每个目标的位置并识别其类别,这自然可以提供丰富的语义信息以及目标位置信息。在这篇论文中,我们的动机是以检测驱动的形式构建一个新的红外和可见光图像融合框架,以便图像融合能够受益于目标检测中包含的语义信息和目标位置信息。
模型
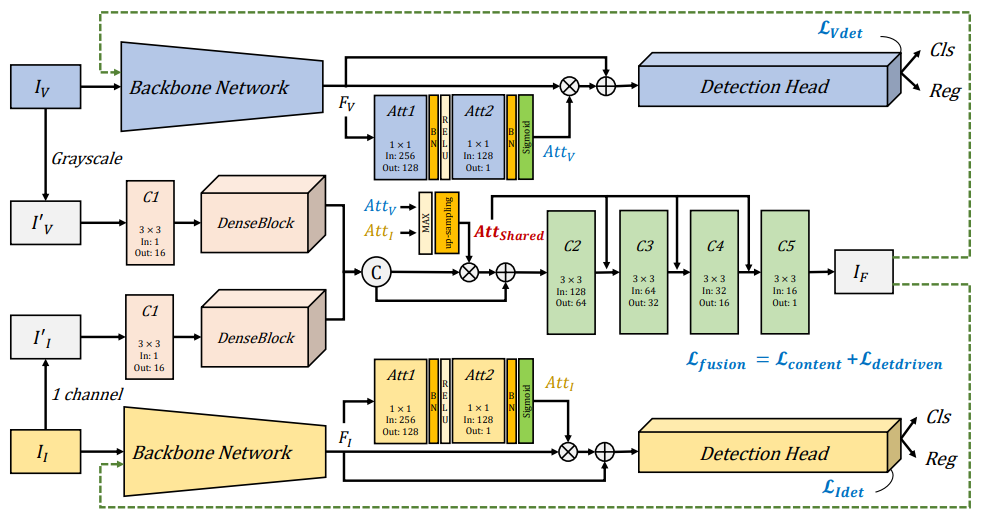
我们提出的DetFusion的框架如图所示,其包含共享注意力引导的融合主网络、可见光检测网络和红外检测网络。每个检测网络由各自的检测损失独立地优化。我们在每个检测器中引入了注意力模块,用于提取可见光特征注意力图和红外特征注意力图。给定输入的一组红外与可见光图像,融合主网络负责生成融合图像,此网络由融合损失来优化。融合损失由基于目标感知的内容损失和检测驱动损失组成。
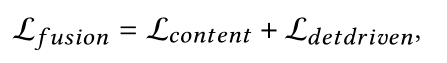
目标检测任务的标注了图像中每个物体的真实位置信息。我们可以使用该位置信息作为先验,自然地找到每个融合图像、红外图像和可见图像中的目标区域和背景区域。因此,我们提出了基于目标感知的内容损失,这促使融合图像基于目标位置先验保持良好的对比度和纹理细节。基于目标感知的内容损失包含目标感知像素损失以及梯度损失。
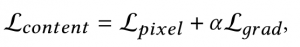
在融合图像中,我们期望目标区域与背景区域相比具有更显著的对比度。因此,目标区域需要保持最大像素强度,背景区域需要稍微低于最大像素强度以显示对象和背景之间的对比度。像素损失针对目标和背景分别采取不同的计算方式。
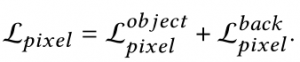
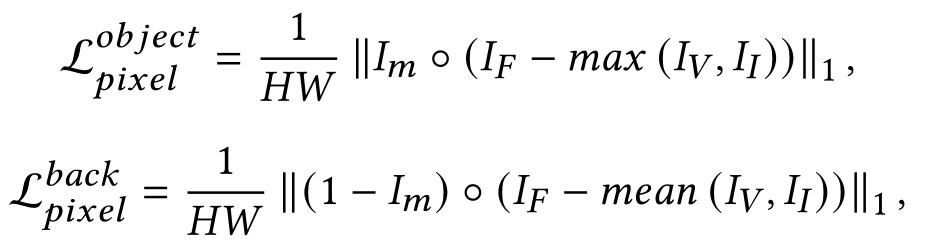
我们期望融合图像保留来自两种模态的图像的最丰富的纹理细节。
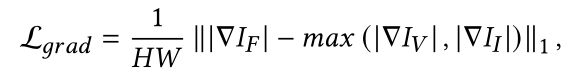
我们将融合图像分别输入红外检测网络和可见光检测网络,并根据各自的预测结果和地面实况计算检测损失。
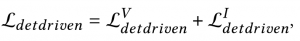
实验

我们在同时支持目标检测与图像融合任务的典型数据集LLVIP和FLIR上进行实验。我们在7个图像融合性能评价指标上对比了7个典型的算法,在两个数据集上进行了定量、定性实验,以及消融实验。这些实验表明了我们的DetFusion的优越性。
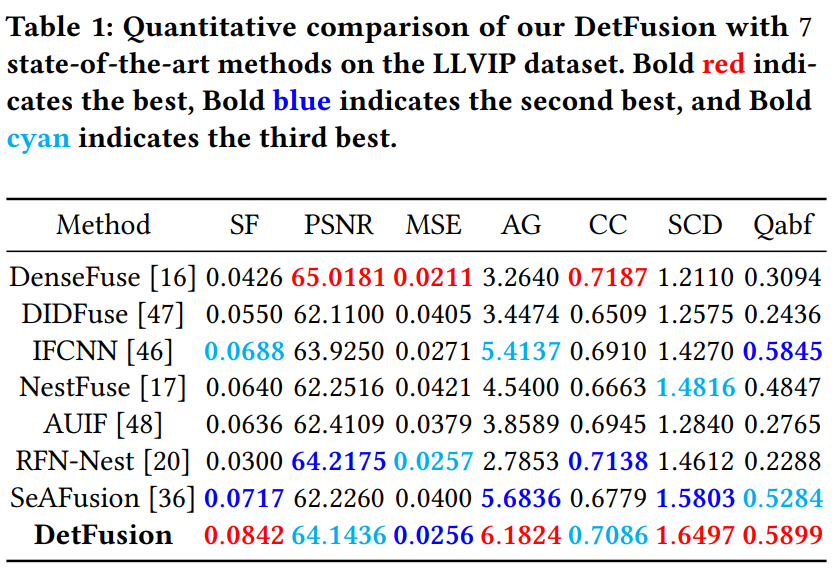
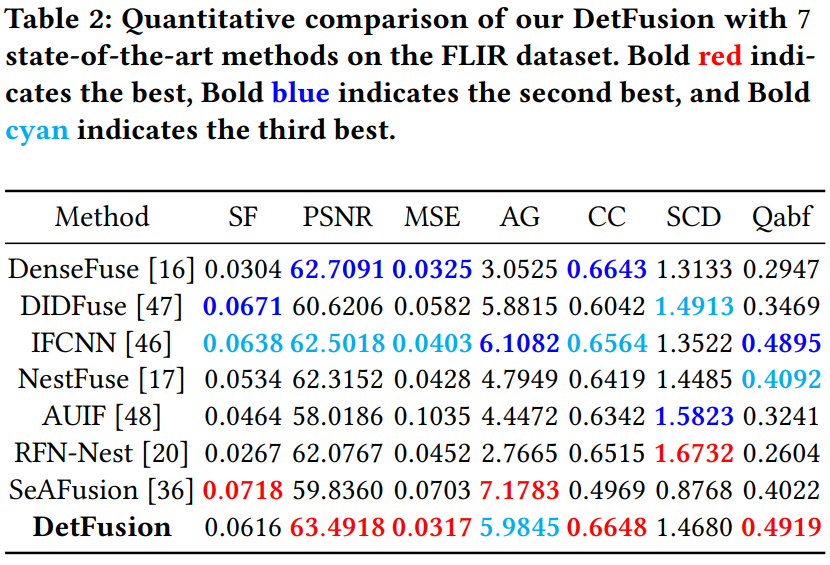


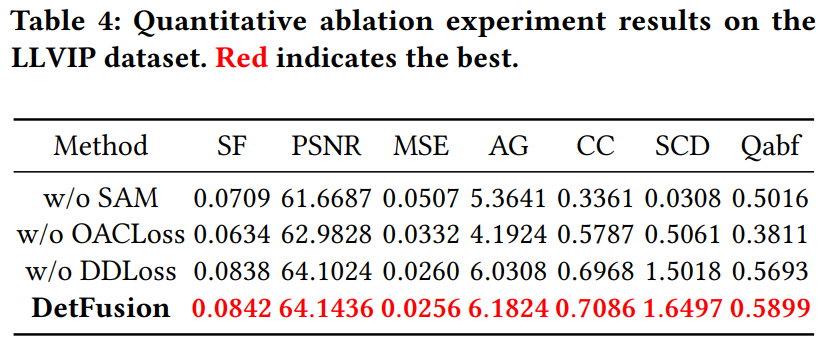
在FLIR数据集和LLVIP数据集上的消融研究也验证了我们框架中每个组件的有效性。