
1.1 引言
自训练作为一种广泛使用的半监督学习策略,产生的伪标签缓解了人群计数中标注耗时费力的问题,在少量有标记数据和大量未标记数据限定下提升了模型的性能。然而密度图的伪标签中的噪声大大阻碍了半监督式人群计数的性能。虽然如二元分割等辅助任务被利用来帮助提高特征表示学习能力,但它们与主要任务,即密度图回归是分离的,多任务关系被完全忽略。为了解决上述问题,我们提出了一个用于人群计数的多任务可信伪标签学习框架(MTCP),由三个多任务分支组成,即密度回归作为主要任务,二元分割和置信度预测作为辅助任务。多任务学习是在标记的数据上进行的 通过为所有三个任务共享相同的特征提取器,并考虑到多任务的关系。为了减少认识上的不确定性,标记的数据被进一步扩展,根据预测的置信度图对标记的数据进行修剪,这可以被看作是一种有效的数据增强策略。对于无标签的数据,与现有的只使用二进制的伪标签的工作相比剖析,我们直接生成可信的密度图的伪标签,这可以减少伪标签中的噪声,从而减少偶然不确定性。在五个人群计数数据集上进行了广泛的比较,证明了我们提出的模型比其他竞争性方法的优越性。
2 方法
给定少量有标注数据![]() 和大量无标注数据
和大量无标注数据![]() , 其中
, 其中![]() 和
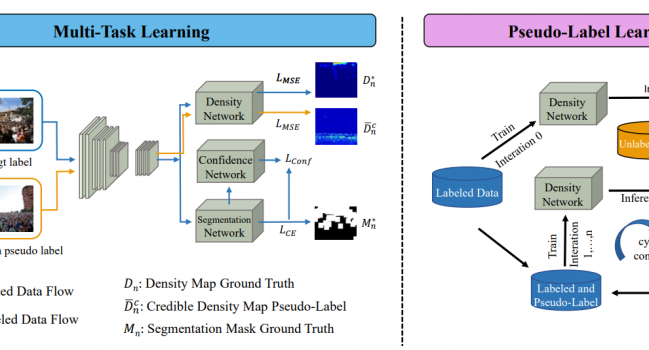
和![]() 分别为密度图和二元分割标注,我们的任务是在此限定下利用大量无标注数据提升计数模型性能。如图1所示,所提出的多任务可信密度图框架由:多任务学习和伪标签学习两个部分组成。
分别为密度图和二元分割标注,我们的任务是在此限定下利用大量无标注数据提升计数模型性能。如图1所示,所提出的多任务可信密度图框架由:多任务学习和伪标签学习两个部分组成。
2.1 多任务学习
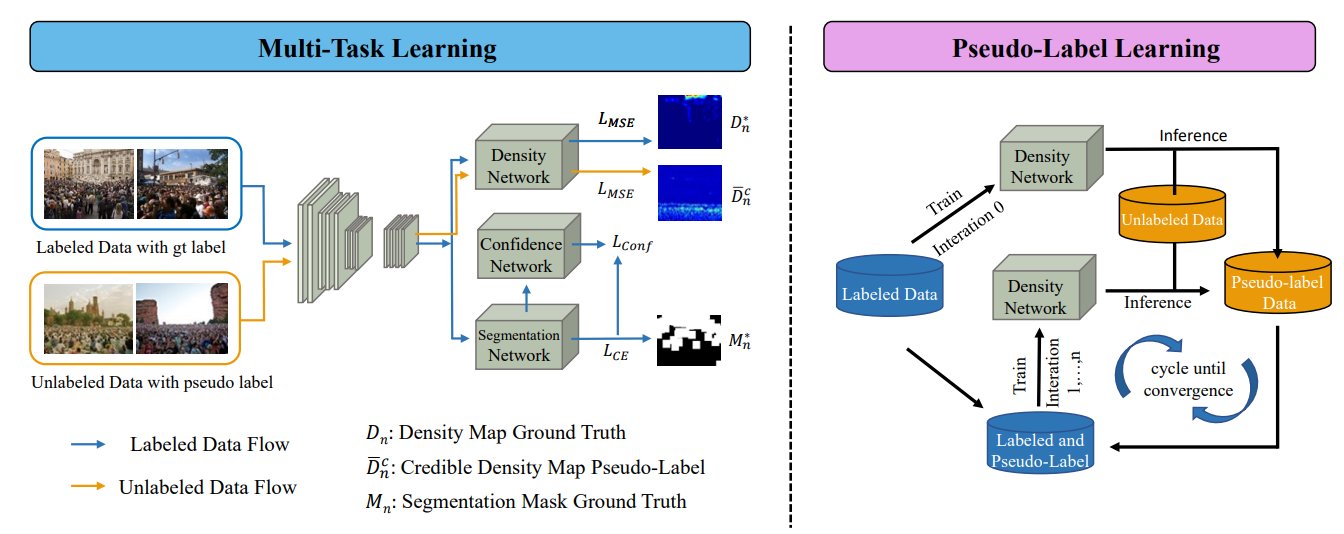
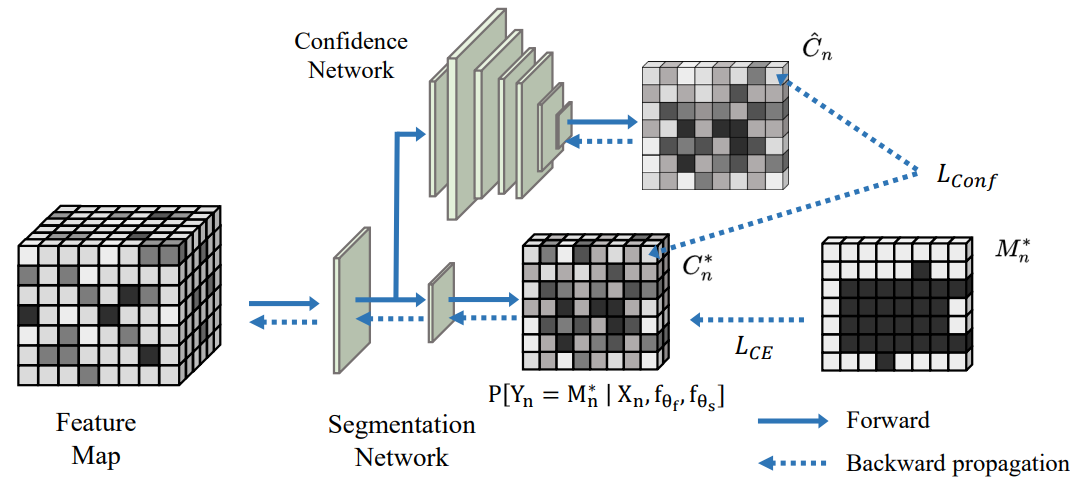
图1左侧展示了多任务学习框架,它包括三个多任务分支。即密度回归、二元分割和置信度预测,其中密度回归是主要任务,而二元分割和置信度预测是辅助任务,三者共享特征提取器。此外,图2展示了置信度网络的监督训练过程,我们基于True Class Probability (TCP) 策略并利用二元分割标注信息指导置信度图预测。
2.2 伪标签学习
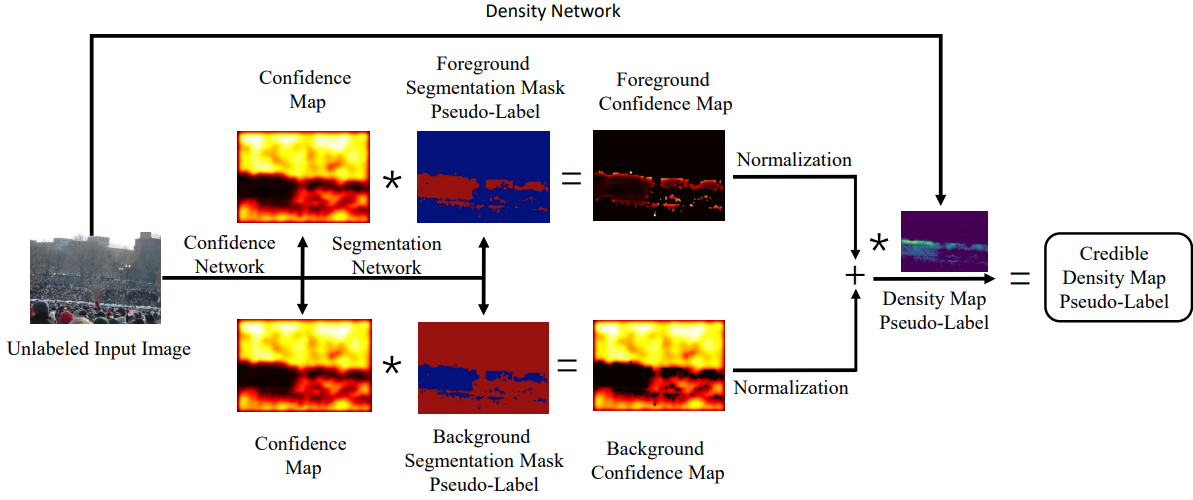
图1右侧展示了伪标签学习迭代过程,对于无标注图像我们使用在上一次迭代中学到的模型进行推断输出密度图的伪标签,循环迭代直至模型收敛。然而伪标签中的噪声会干扰模型学习过程,我们基于多任务学习框架生成可信密度图伪标签,具体为图3所示。
3 实验结果
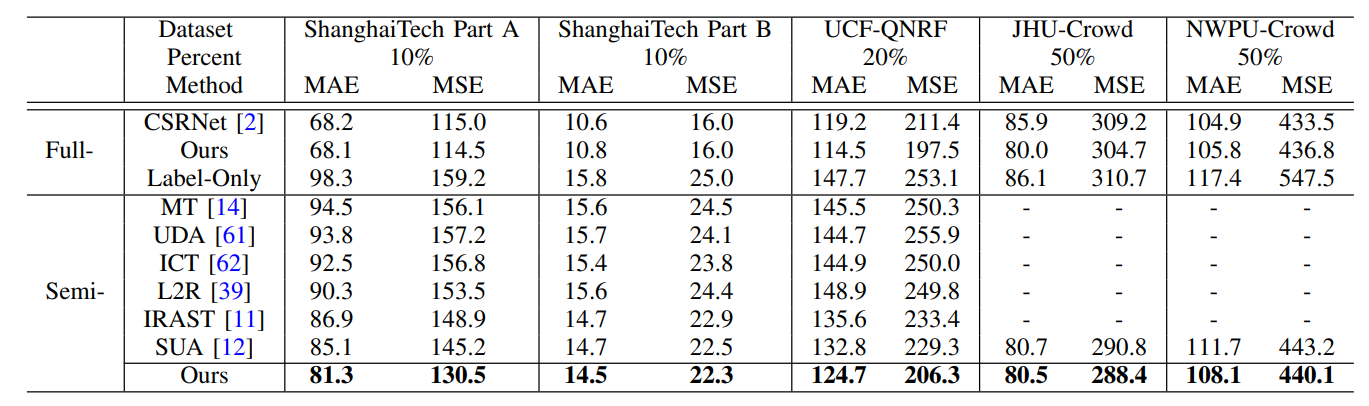
我们在SHA,SHB,UCF-QNRF,JHU-Crowd, NWPU-Crowd人群计数数据集上用实验表明了我们模型的有效性。

数据和代码链接:https://github.com/ljq2000/MTCP.