
1. 摘要
开放环境中包含已知类样本和大量的未知新类样本。开放集识别要求分类器不仅可以对已知类样本进行分类,同时还可以对未知新类样本进行检测。对于某个的分类模型,它的闭集分类精度和新类检测精度是什么关系?目前的主流观点是模型的闭集分类精度和新类检测精度是正相关的,本工作则指出两者是一种trade-off的关系。本工作从trade-off的角度回顾现有正则化方法,并提出一种负样本生成策略和方法——OpenMix。相比于现有方法,OpenMix能实现更好的trade-off 。
2. 回顾传统闭集正则化方法
闭集正则化方法用于提升闭集分类精度。从对新类检测精度的影响的角度,本工作回顾了几种流行的正则化方法:
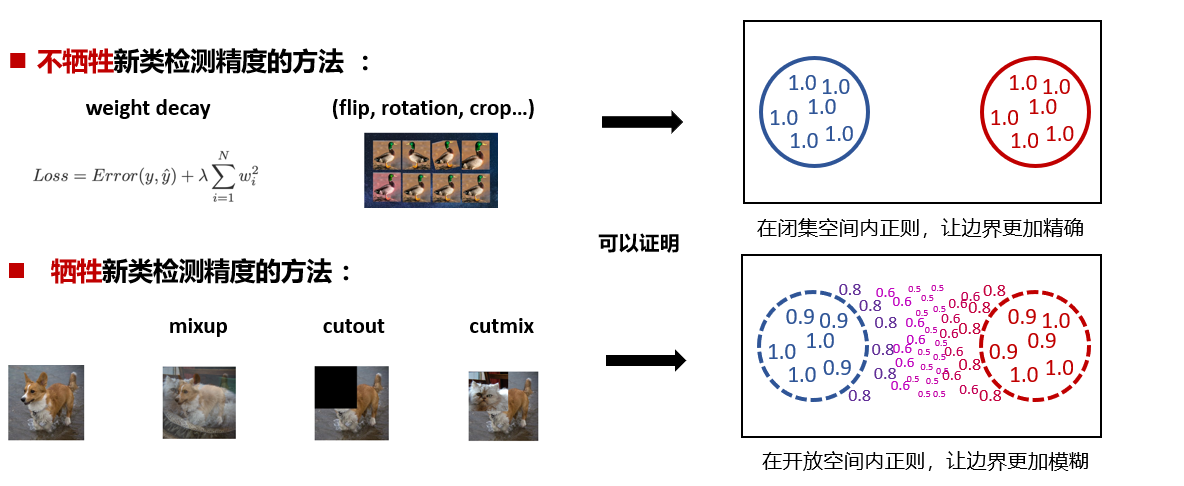
本工作从理论和实验两个角度说明了在闭集空间内正则的传统闭集正则化方法可以实现更好的trade-off,如 weight decay,flip,rotation,crop。
3. 回顾负样本增强方法
负样本增强方法用于提升新类检测精度。从对闭集分类精度影响的角度,本工作回顾了几种负样本增强方法:
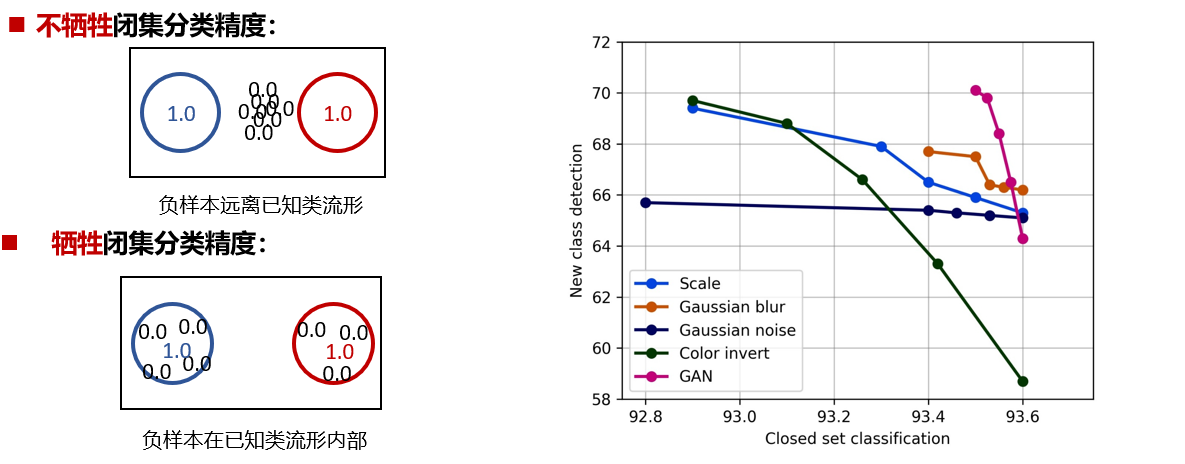
本工作从理论和实验两个角度说明了现有几种负样本增强方法在闭集分类精度和开集检测精度之间往往顾此失彼。
4. OpenMix
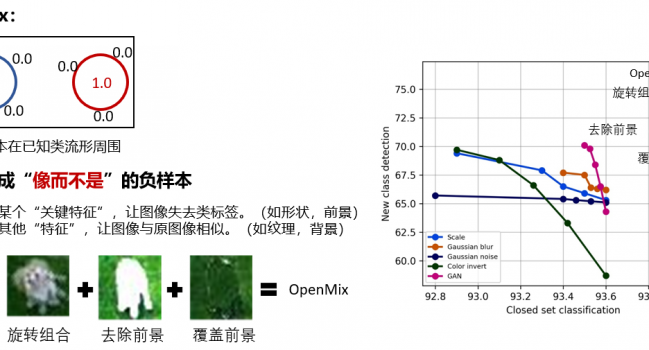
本文从trade-off的角度提出了一种新的负样本增强方法——OpenMix。OpenMix可以生成“像而不是”的负样本,它们包裹在已知类流形周围,可以在不损失闭集分类精度的基础上,更有效的提升新类检测精度,从而实现更好的trade-off。
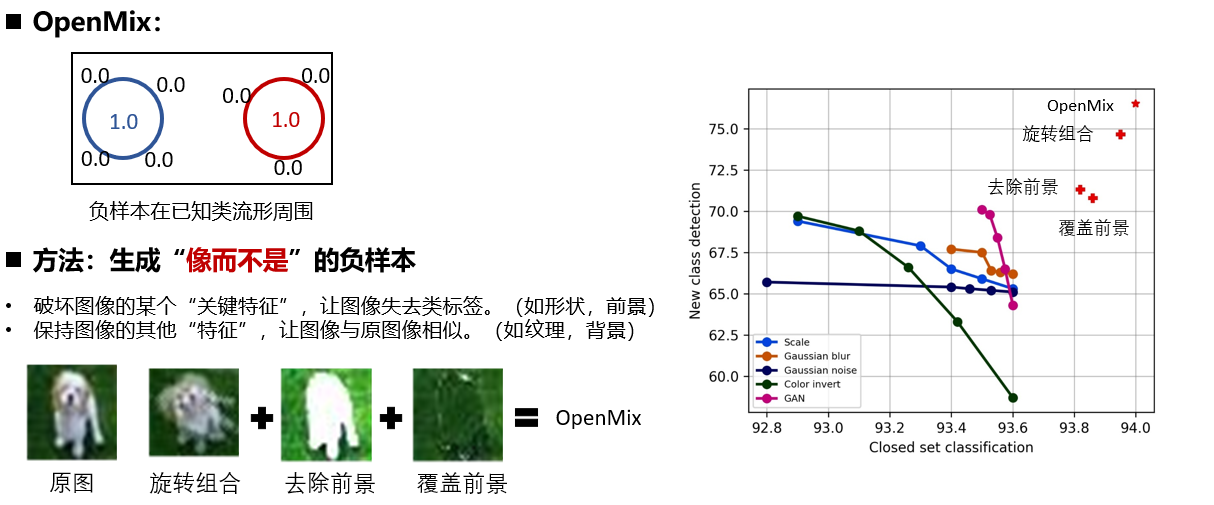
5. OpenMix+
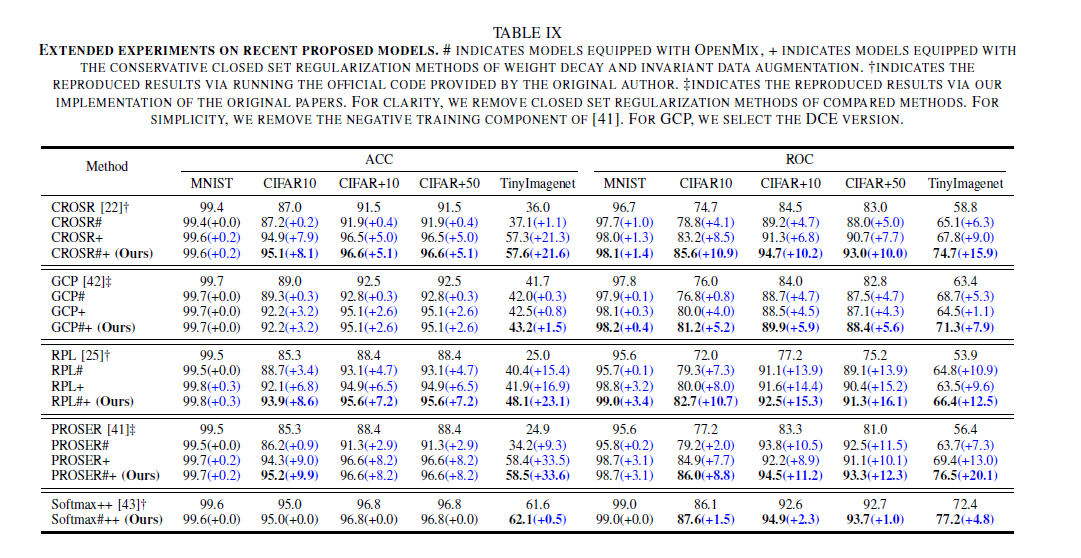
将 OpenMix 与 weight decay,flip,rotation,crop 组合成 OpenMix+,能帮助各种开放集模型在各种 benchmark 数据集上实现出色的trade-off。